DS2404_3
Hayashi Atsuhiro
2024/10/24
3. グループごとの集計
3.1. グループごとの基礎統計量
分析を進めていく過程において、男女別の体格を比較する等、 データの中の属性(群)ごとの集計を行うことによって、 より詳細に当該現象を理解することができる場面がある。 そのためには、群を分離する工程が必要になる。
以下では身長について、男女を区別しない集団、及び、女だけ・男だけの集団の 基礎統計量を求めている。 指定の理解にはややパズル的な要素が必要である。 頭が混乱するようであれば、より細かい単位の指定を各自で指定した変数に置いて 逐次確認するようにすれば理解が早まるのではないか。
dim(Student24) # 全データ(男女を区別しない集団)のサンプルサイズ## [1] 792 9summary(Student24$Height) # 全データの、身長の基礎統計量## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 145.0 164.0 170.0 168.9 175.0 187.0 41Student24_MF<-Student24[!is.na(Student24$Sex),] # 性別がNAのサンプルを除去(性別がMかFの者だけ)
dim(Student24_MF) # 性別を回答した集団の、サンプルサイズ## [1] 658 9Student24_MF # 性別がNAのサンプルを除去(性別がMかFの者だけ)
No Sex Height Weight Chest Residence Remittance Carrier Fee
1 1 F 145.0 38 NA 自宅生 10000 <NA> NA
2 2 F 145.5 42 76 自宅生 0 <NA> 3700
3 3 F 146.7 41 85 自宅生 10000 Vodafone 6000
4 4 F 148.0 42 NA 自宅生 50000 <NA> NA
5 5 F 148.0 43 80 自宅生 50000 DoCoMo 4000
6 6 F 148.9 NA NA 自宅生 60000 <NA> NA
7 7 F 149.0 45 NA 下宿生 60000 <NA> NA
8 8 F 150.0 43 82 自宅生 0 <NA> 4980
9 9 F 150.0 46 86 <NA> 40000 <NA> NA
10 10 F 150.0 47 NA 自宅生 NA <NA> NA
11 11 F 151.0 42 NA 自宅生 NA <NA> 7700
[ reached 'max' / getOption("max.print") -- omitted 647 rows ]
Student24$Sex[1:100] # 元データのSexカラム## [1] "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" NA "F" "F" "F" "F" "F"
## [19] "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" NA "F" "F" "F"
## [37] NA "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "M" "F" "F" "F" "F" "F" "F"
## [55] "F" "F" "F" "F" "M" "F" "F" NA "F" "F" "F" "F" "F" "F" "F" "F" "F" "F"
## [73] "F" "F" "M" "F" NA "F" NA "F" "F" "F" "F" "F" "F" NA "F" "F" "F" "F"
## [91] "F" "F" "F" "F" "F" "M" "M" "F" "F" "F"Student24_MF$Sex[1:100] # 性別がNAのサンプルを除去したSexカラム## [1] "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F"
## [19] "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F"
## [37] "F" "F" "F" "F" "F" "F" "F" "F" "M" "F" "F" "F" "F" "F" "F" "F" "F" "F"
## [55] "F" "M" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "M" "F"
## [73] "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "F" "M" "M"
## [91] "F" "F" "F" "F" "F" "F" "M" "F" "M" "M"summary(Student24_MF$Height) # 性別を回答した集団の、身長の基礎統計量## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 145.0 163.0 170.0 168.5 174.0 186.5 28dim(Student24_MF[Student24_MF$Sex=="F",]) # 女の集団の人数## [1] 183 9summary(Student24_MF[Student24_MF$Sex=="F",]$Height) # 女の集団の身長の基礎統計量## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 145.0 156.0 160.0 159.1 163.0 171.0 15sd(Student24_MF[Student24_MF$Sex=="F",]$Height, na.rm=TRUE) # 女だけの集団の身長の標準偏差## [1] 5.214718dim(Student24_MF[Student24_MF$Sex=="M",]) # 男の集団の人数## [1] 475 9summary(Student24_MF[Student24_MF$Sex=="M",]$Height) # 男の集団の身長の基礎統計量## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 156.0 168.0 172.0 171.9 175.8 186.5 13sd(Student24_MF[Student24_MF$Sex=="M",]$Height, na.rm=TRUE) # 男だけの集団の身長の標準偏差## [1] 5.551883[演習3.1-1] 以下は何を求めるための式なのか。女だけが抽出できているか? 上記の式の結果と比較して微妙に異なっているが、どの値を用いるのが正しいのか。なぜこのようなことが起こるのかを考えてみよ。
Student24$Sex=="F" # 女だけにTRUE?
summary(Student24$Sex=="F")
Student24[Student24$Sex=="F",] # 女だけのデータを抽出?
summary(Student24[Student24$Sex=="F",])
Student24[Student24$Sex=="F",]$Height # 女だけの身長のデータ?
summary(Student24[Student24$Sex=="F",]$Height)
mean(Student24[Student24$Sex=="F",]$Height) # 女だけの身長の平均?
summary(Student24[Student24$Sex=="F",]$Height) # 女だけの身長の基礎統計量?3.2. グループごとのヒストグラムや箱ひげ図
視覚的に比較するにはグループごとのヒストグラムを描けば良い。 その際、縦軸、横軸の範囲や、横軸の区切り幅を同一にしておかないと 比較が困難になるので陽に指定する方法を紹介する。 結果を比較してもらいたいのだが、男の分布の方が右側にシフトしていることが判るであろうか。
# 女だけのヒストグラム
hist(Student24[Student24$Sex=="F",]$Height,
breaks=seq(140,190,5), ylim=c(0,160),
xlab="Female", main="Histogram of Height")
abline(h=seq(0,160,20), lty=3)
# 男だけのヒストグラム
hist(Student24[Student24$Sex=="M",]$Height,
breaks=seq(140,190,5), ylim=c(0,160),
xlab="Male", main="Histogram of Height")
abline(h=seq(0,160,20), lty=3)
[演習3.2-1] 男女それぞれを縦軸、横軸の範囲や横軸の区切り幅を指定せずに描画してみよ。比較し辛いことが解るであろう。
【参考1】2つのグラフを左右に並べて配置
# 図を左右に並べて表示
par(mfrow=c(1,2)) # 行列のイメージ。1行2列で配置を準備
# 女だけのヒストグラム
hist(Student24[Student24$Sex=="F",]$Height,
breaks=seq(140,190,5), ylim=c(0,160),
xlab="Female", main="Histogram of Height")
abline(h=seq(0,160,20), lty=3)
# 男だけのヒストグラム
hist(Student24[Student24$Sex=="M",]$Height,
breaks=seq(140,190,5), ylim=c(0,160),
xlab="Male", main="Histogram of Height")
abline(h=seq(0,160,20), lty=3)
# 図を左右に並べる設定を解除。
par(mfrow=c(1,1))【参考2】2つのグラフを重ねて配置
他にも2つのヒストグラムを重ねて表示する方法もある。
# 2つのヒストグラムを重ねて表示する
hist(Student24[Student24$Sex=="F",]$Height,
breaks=seq(140,190,5), xlim=c(140,190), ylim=c(0,160),
col="#FF00007F",
main="Histogram of Student's Height", xlab="Shintyou" )
hist(Student24[Student24$Sex=="M",]$Height,
breaks=seq(140,190,5), xlim=c(140,190), ylim=c(0,160),
col="#0000FF7F", add=T)
abline(h=seq(0,160,20), lty=3)
【参考3】Rの色指定いろいろ
- 色の指定方法が紹介されているので参考になるのではないか。
また、箱ひげ図に対しては2つの指定方法があるので、好みの方を利用すれば良い。
# 箱ひげ図(指定方法1)
boxplot(Student24[Student24$Sex=="F",]$Height,
Student24[Student24$Sex=="M",]$Height,
names=c("Female", "Male"))
abline(h=seq(150,180,10), lty=3)
# 箱ひげ図(指定方法2、こちらの方が短くて済む)
boxplot(Height~Sex, data=Student24)
abline(h=seq(150,180,10), lty=3)
[演習3.2-2] 上記では身長について、男女比較を行った。他の変量でも男女比較を行って、属性ごとの特徴を把握してみよ。
4. 変量の切り出し
これまでは、収集したデータの全変量を引き継いできたが、 指定するための式が複雑になり混乱すると感じるのであれば、 分析に必要な変量だけを分析に先立って切り出しておいて利用する手もある。
例えば、分析対象の変量が確定した段階で、欠損値を含むデータを除外(完全データ)した変数を新たに定義して(切り出して)、以後はそちらの変数を利用するようにすると 作業が楽になる。
# データ切り出し(性別と体格の、4変量を保存した新たな変数を作成
Student24_SexBody<-Student24[,2:5]Student24_SexBody
Sex Height Weight Chest
1 F 145.0 38.0 NA
2 F 145.5 42.0 76
3 F 146.7 41.0 85
4 F 148.0 42.0 NA
5 F 148.0 43.0 80
6 F 148.9 NA NA
7 F 149.0 45.0 NA
8 F 150.0 43.0 82
9 F 150.0 46.0 86
10 F 150.0 47.0 NA
11 F 151.0 42.0 NA
12 F 151.0 45.0 NA
13 <NA> 151.0 46.0 NA
14 F 151.0 50.0 NA
15 F 151.0 NA NA
16 F 151.7 41.5 80
17 F 152.0 35.0 77
18 F 152.0 43.0 NA
19 F 152.0 44.0 NA
20 F 152.0 45.0 NA
21 F 153.0 41.0 NA
22 F 153.0 42.0 NA
23 F 153.0 46.5 87
24 F 153.0 50.0 NA
25 F 153.0 55.0 78
[ reached 'max' / getOption("max.print") -- omitted 767 rows ]
# 変量の指定方法(以下は身長を指定する2通りの表記方法である)
Student24_SexBody$Height # 指定方法1
[1] 145.0 145.5 146.7 148.0 148.0 148.9 149.0 150.0 150.0 150.0 151.0 151.0
[13] 151.0 151.0 151.0 151.7 152.0 152.0 152.0 152.0 153.0 153.0 153.0 153.0
[25] 153.0 153.0 153.0 153.0 153.0 153.5 154.0 154.4 155.0 155.0 155.0 155.0
[37] 155.0 155.0 155.0 156.0 156.0 156.0 156.0 156.0 156.0 156.0 156.0 156.0
[49] 156.0 156.0 156.0 156.0 156.0 156.0 156.5 156.5 157.0 157.0 157.0 157.0
[61] 157.0 157.0 157.0 157.0 157.0 157.8 158.0 158.0 158.0 158.0 158.0 158.0
[73] 158.0 158.0 158.0 158.0 158.0 158.0 158.0 159.0 159.0 159.0 159.0 159.0
[85] 159.0 159.0 159.0 159.0 159.0 159.0 159.5 160.0 160.0 160.0 160.0 160.0
[97] 160.0 160.0 160.0 160.0
[ reached getOption("max.print") -- omitted 692 entries ]
Student24_SexBody[,2] # 指定方法2
[1] 145.0 145.5 146.7 148.0 148.0 148.9 149.0 150.0 150.0 150.0 151.0 151.0
[13] 151.0 151.0 151.0 151.7 152.0 152.0 152.0 152.0 153.0 153.0 153.0 153.0
[25] 153.0 153.0 153.0 153.0 153.0 153.5 154.0 154.4 155.0 155.0 155.0 155.0
[37] 155.0 155.0 155.0 156.0 156.0 156.0 156.0 156.0 156.0 156.0 156.0 156.0
[49] 156.0 156.0 156.0 156.0 156.0 156.0 156.5 156.5 157.0 157.0 157.0 157.0
[61] 157.0 157.0 157.0 157.0 157.0 157.8 158.0 158.0 158.0 158.0 158.0 158.0
[73] 158.0 158.0 158.0 158.0 158.0 158.0 158.0 159.0 159.0 159.0 159.0 159.0
[85] 159.0 159.0 159.0 159.0 159.0 159.0 159.5 160.0 160.0 160.0 160.0 160.0
[97] 160.0 160.0 160.0 160.0
[ reached getOption("max.print") -- omitted 692 entries ]
加えて、欠損値を含むサンプル全部を除外する(完全データと呼ぶ)には
na.omit()関数を用いる。以下の操作により除外されたことを確認せよ。
dim(Student24_SexBody) # 除外前のデータサイズ## [1] 792 4summary(Student24_SexBody) # 除外前のデータの概観## Sex Height Weight Chest
## Length:792 Min. :145.0 Min. : 35.00 Min. : 30.50
## Class :character 1st Qu.:164.0 1st Qu.: 53.38 1st Qu.: 82.25
## Mode :character Median :170.0 Median : 60.00 Median : 87.00
## Mean :168.9 Mean : 59.93 Mean : 86.08
## 3rd Qu.:175.0 3rd Qu.: 65.00 3rd Qu.: 90.00
## Max. :187.0 Max. :100.00 Max. :112.00
## NA's :41 NA's :100 NA's :550# 欠損値を含むサンプルを除外
Student24_SexBody_noNA<-na.omit(Student24_SexBody)Student24_SexBody_noNA
Sex Height Weight Chest
2 F 145.5 42.0 76
3 F 146.7 41.0 85
5 F 148.0 43.0 80
8 F 150.0 43.0 82
9 F 150.0 46.0 86
16 F 151.7 41.5 80
17 F 152.0 35.0 77
23 F 153.0 46.5 87
25 F 153.0 55.0 78
26 F 153.0 57.0 38
32 F 154.4 44.0 75
34 F 155.0 48.0 83
40 F 156.0 42.0 85
42 F 156.0 46.0 82
44 F 156.0 48.0 70
45 F 156.0 49.0 85
46 F 156.0 50.0 82
48 M 156.0 61.0 90
55 F 156.5 45.0 80
61 F 157.0 53.0 84
66 F 157.8 52.0 83
68 F 158.0 46.0 80
70 F 158.0 48.0 80
71 F 158.0 49.0 85
73 F 158.0 50.0 85
[ reached 'max' / getOption("max.print") -- omitted 173 rows ]
dim(Student24_SexBody_noNA) # 除外後のデータサイズ## [1] 198 4summary(Student24_SexBody_noNA) # 除外後のデータの概観## Sex Height Weight Chest
## Length:198 Min. :145.5 Min. : 35.00 Min. : 38.00
## Class :character 1st Qu.:163.0 1st Qu.: 53.00 1st Qu.: 82.25
## Mode :character Median :169.2 Median : 60.00 Median : 86.50
## Mean :168.3 Mean : 60.39 Mean : 86.28
## 3rd Qu.:173.7 3rd Qu.: 66.92 3rd Qu.: 90.00
## Max. :185.0 Max. :100.00 Max. :112.00上記の過程を経ると、欠損値を含まない「完全データだけ」が抽出できる。 そのことは、データサイズの変化でも理解できるであろう。
[演習4-1] 以下は第1節で紹介した相関係数を算出するプログラムである。
この節で新規に作成した変数Student24_SexBodyとStudent24_SexBody_noNAに対して、 それぞれ3通りの計算を行っている。 計算結果を比較すると微妙に数値が異なっている部分がある。 それぞれの出力は何を対象に相関係数を計算しているか理解できるか。 例えば身長と体重の相関係数はどの出力の値を用いれば良いのか。 違いを含めて理由を推察せよ。
# 欠損値を含んだデータに対する相関行列の計算
cor(Student24_SexBody[,2:4]) # オプションを指定せず
cor(Student24_SexBody[,2:4],
use="pairwise.complete.obs") # 欠損値を含んでいる対を除外(計算方法1)
cor(Student24_SexBody[,2:4],
use="complete.obs") # 1変量でも欠損値を含んでいるサンプルはサンプル自身を除外(計算方法2)# 欠損値を除外したデータに対する相関行列の計算
cor(Student24_SexBody_noNA[,2:4]) # オプションを指定せず
cor(Student24_SexBody_noNA[,2:4],
use="pairwise.complete.obs") # 欠損値を含んでいる対を除外(計算方法1)
cor(Student24_SexBody_noNA[,2:4],
use="complete.obs") # 1変量でも欠損値を含んでいるサンプルはサンプル自身を除外(計算方法2)5. 「平均値」の意味するもの : 中間? 真ん中? 代表値? 大体の目安?
-
ある記事に『平均貯蓄額1904万円』とある。:
All About 2024.6.18
- 妥当なのか? 高いのか? 低いのか?
-
「真ん中」を代表する 3つの指標 :
- 平均値(Mean)、最頻値(Mode)、中央値(中位数, Median)
- それぞれ、何を表している指標なのか?
-
2023年(令和5年)における「一世帯当りの貯蓄額」を例に三者の関係を把握しよう。 総務省 統計局 が公表している「 家計調査 」の中の「 調査の結果 」─「 結果の概要 / 貯蓄・負債編 」─「 家計調査報告(貯蓄・負債編)-2023年(令和5年)平均結果-(二人以上の世帯) 」の第2節 には、全世帯の貯蓄高を例に、2つの指標が図示されているので、 これらの関係が理解しやすいであろう。 平均値だけを用いた判断がいかに危ういことかが説明されている。 ここでは一つの図だけを引用しておくが、詳しくは本文を参照されたい。
-
なお、これら資料を読む際には、「 家計調査のしくみと見方 」の中の 「 第3 家計調査の貯蓄・負債編の見方 」が参考になるであろう。
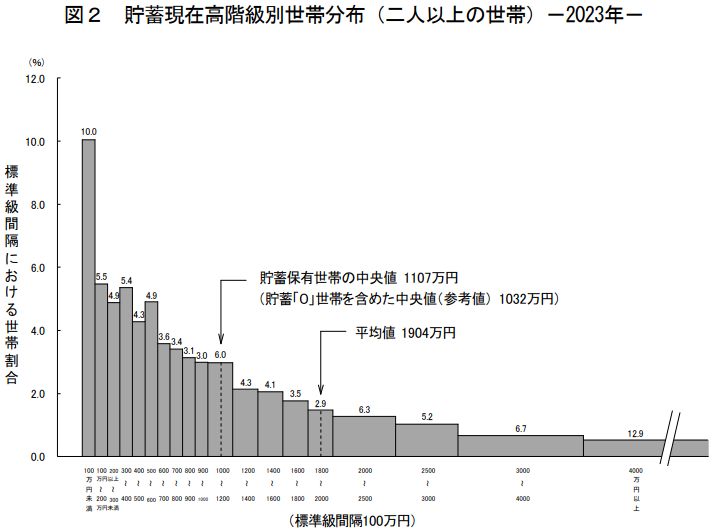
分布形状と統計量
- 「平均値」の意味するもの : 期待値。一つの指標に過ぎない。
- 分布形状 : 対称分布の場合だけ「印象」と合致する。
- 非対称の場合は裾の長い方にずれ、特に外れ値があると間違った「印象」を与えかねない。
- 分布の偏り : 常にあると思っておいた方がよい。
- 非対称の場合には、最頻値や中央値(中位数)も吟味する必要がある。
-
少数例では、分布形状が明確にならない。
- (「平均値」の恣意的・意図的利用が散見される。)
- 平均値の意味するもの : 対称分布の時だけイメージが一致する
6. 利用方法の体得、関数の把握 & データ収集
4週にわたってR&RStudioの使い方を説明してきた。 その中には、欠損値の取り扱い方も含まれる。 ここまで習得できれば一応各自で最低限の分析はできると考えている。 講義の中で紹介したプログラムを参考に自分の目的に合わせたプログラムに 改変・利用できる技量を身に付けてほしいと考えている。 今後は、より新しい統計手法に関する関数を習得する方にシフトしていく。
第1回でも予告したように後期前半を総括する課題として 以下二重枠囲み内の宿題を挙げてある。 各自のデータを見つけること、及び、そのデータに対して習得した関数を試しに適用して分析してみることを推奨しておく。
これも既にお伝えしたが、この講義の評価は前半と後半で分かれており、前半部で1回評価が入る。
課題を課す段階で提出期限を設けるが、
指定した期日(今後相談)を過ぎたものは評価対象としませんのでご注意下さい。
参考までに「多変量解析に適用する」際には、
余りサンプル数が少ない(少数例)や変量数の少ないデータだと適用できなかったり、
適用しても興味深い知見が得られないことが多いので、データを収集する際に注意してください。
加えて、集計済みのデータではなく、個票データの方が細かな分析に耐えると思われる。
データの引用元に取り立てての制限はないので、身の回りにある新聞、雑誌、書籍、ご自身の調査等いろいろなところから持ち込んでくれればと思いますが、 例えばDragonsデータで紹介したようにWeb上にもデータを収録・掲載しているサイトがあり、 以下のようなものもその取っ掛かりになるのではないか。
- [例示] e-Stat 政府統計ポータルサイト
【第1回の再掲】7. 前半7回を通しての宿題
今回は、RStudioを通してRを使ってみた。 現時点ではまだ自分でプログラムが組めるようになるとは思えないかもしれないが、順に習得していってくれればと思う。 また、プログラムを組むことも大事だが、 得られた数値(統計量)をどのように解釈するかにも注意を払えるようになってほしいと思っている。
【前半レポートの案】「ご自身が興味を持ったデータ」を分析して報告してもらう。- 前半7回を終えるにあたって、各自で用意したデータを分析しレポートとして提出してもらおうと考えている。そこで「ご自身が興味のあるデータ」を見つけてきてほしい。電子化し、分析・報告してもらおうと考えているが、持参後の手順等は今後順に紹介するので、まずは「興味あるデータ」を各自 自力で見つけてきてほしい。 身の回りのデータに注意を払うことを習慣にすると良いかも。
- 5-6回が終わる頃までには確定すること。そうしないとレポートが書けない=単位を出せない。
7.【問】回帰直線って何? ===> 次回
- 何に使う?
- どうやって決める?
- 何に使える?
- そもそも、どういう考えから導き出された?
- 回帰直線はどうやって確定する?
- 回帰分析とは?
## Warning in StudTmp$Height + tmpRand[1:772] * 0.2:
## 長いオブジェクトの長さが短いオブジェクトの長さの倍数になっていません## Warning in StudTmp$Weight + tmpRand[1001:1772] * 0.2:
## 長いオブジェクトの長さが短いオブジェクトの長さの倍数になっていません
[注意1]
散布図を丁寧に観るとデータの稠密な部分と疎な部分があることを理解せよ。
[注意2]
ここに掲載している散布図は、視覚的に密度を理解し易くするために、第3回の第3節で紹介した、乱数を用いて描画点をブレさせて表示してある。
その理由は、身長や体重は記憶に頼っていることもあり離散量として回答されているので、そのまま生データをプロットすると(以下散布図参照)、同じポイントは重なって表示され(重なっている数は読み取れない)、また、「縞模様」状になってしまう。
そこで、「一種のテクニック」として、各プロット点に微小な乱数を乗せて
(微妙に揺らして)描画することにより密度が視覚的に理解できるようになる。
言うまでも無いだろうが、あくまでも散布図をプロットする際のテクニックであり、
(回帰)分析に用いるデータに乱数を付加しているわけではない。
【解説用に追加】第3回第3節に散布図として掲載済み

8. [参考] 読み物
- 西内 啓著、「 統計学が最強の学問である 」、2013/1/24、¥ 1,760
-
竹村 彰通著、「
データサイエンス入門
」、 (岩波新書) 新書、2018/4/21、¥968
- ダレル・ハフ著, 高木 秀玄翻訳、「 統計でウソをつく法―数式を使わない統計学入門 」、(ブルーバックス)、1968/7/24、¥1012
- デイヴィッド・サルツブルグ著, 竹内惠行&熊谷悦生翻訳、「 統計学を拓いた異才たち 」、2010/4/1、¥2844
82. 参考
このページで取り扱ったプログラムだけを抜き出して以下に列挙しておく。
## 3.1. グループごとの基礎統計量
dim(Student24) # 全データ(男女を区別しない集団)のサンプルサイズ
summary(Student24$Height) # 全データの、身長の基礎統計量
Student24_MF<-Student24[!is.na(Student24$Sex),] # 性別がNAのサンプルを除去(性別がMかFの者だけ)
dim(Student24_MF) # 性別を回答した集団の、サンプルサイズ
Student24_MF # 性別がNAのサンプルを除去(性別がMかFの者だけ)
Student24$Sex[1:100] # 元データのSexカラム
Student24_MF$Sex[1:100] # 性別がNAのサンプルを除去したSexカラム
summary(Student24_MF$Height) # 性別を回答した集団の、身長の基礎統計量
dim(Student24_MF[Student24_MF$Sex=="F",]) # 女の集団の人数
summary(Student24_MF[Student24_MF$Sex=="F",]$Height) # 女の集団の身長の基礎統計量
sd(Student24_MF[Student24_MF$Sex=="F",]$Height, na.rm=TRUE) # 女だけの集団の身長の標準偏差
dim(Student24_MF[Student24_MF$Sex=="M",]) # 男の集団の人数
summary(Student24_MF[Student24_MF$Sex=="M",]$Height) # 男の集団の身長の基礎統計量
sd(Student24_MF[Student24_MF$Sex=="M",]$Height, na.rm=TRUE) # 男だけの集団の身長の標準偏差
## [演習3.1-1]
Student24$Sex=="F" # 女だけにTRUE?
Student24[Student24$Sex=="F",] # 女だけのデータを抽出?
Student24[Student24$Sex=="F",]$Height # 女だけの身長のデータ?
mean(Student24[Student24$Sex=="F",]$Height) # 女だけの身長の平均?
summary(Student24[Student24$Sex=="F",]$Height) # 女だけの身長の基礎統計量?
## 3.2. グループごとのヒストグラムと箱ひげ図
# 女だけのヒストグラム
hist(Student24[Student24$Sex=="F",]$Height,
breaks=seq(140,190,5), ylim=c(0,160),
xlab="Female", main="Histogram of Height")
abline(h=seq(0,160,20), lty=3)
# 男だけのヒストグラム
hist(Student24[Student24$Sex=="M",]$Height,
breaks=seq(140,190,5), ylim=c(0,160),
xlab="Male", main="Histogram of Height")
abline(h=seq(0,160,20), lty=3)
## 【参考1】2つのグラフを左右に並べて配置
# 図を左右に並べて表示
par(mfrow=c(1,2)) # 行列のイメージ。1行2列で配置を準備
# 女だけのヒストグラム
hist(Student24[Student24$Sex=="F",]$Height,
breaks=seq(140,190,5), ylim=c(0,160),
xlab="Female", main="Histogram of Height")
abline(h=seq(0,160,20), lty=3)
# 男だけのヒストグラム
hist(Student24[Student24$Sex=="M",]$Height,
breaks=seq(140,190,5), ylim=c(0,160),
xlab="Male", main="Histogram of Height")
abline(h=seq(0,160,20), lty=3)
# 図を左右に並べる設定を解除。
par(mfrow=c(1,1))
## 【参考2】2つのグラフを重ねて配置
# 2つのヒストグラムを重ねて表示する
hist(Student24[Student24$Sex=="F",]$Height,
breaks=seq(140,190,5), xlim=c(140,190), ylim=c(0,160),
col="#FF00007F",
main="Histogram of Student's Height", xlab="Shintyou" )
hist(Student24[Student24$Sex=="M",]$Height,
breaks=seq(140,190,5), xlim=c(140,190), ylim=c(0,160),
col="#0000FF7F", add=T)
abline(h=seq(0,160,20), lty=3)
# 箱ひげ図(指定方法1)
boxplot(Student24[Student24$Sex=="F",]$Height,
Student24[Student24$Sex=="M",]$Height,
names=c("Female", "Male"))
abline(h=seq(150,180,10), lty=3)
# 箱ひげ図(指定方法2、こちらの方が短くて済む)
boxplot(Height~Sex, data=Student24)
abline(h=seq(150,180,10), lty=3)
## 4. 変量の切り出し
# データ切り出し(性別と体格の、4変量を保存した新たな変数を作成
Student24_SexBody<-Student24[,1:4]
Student24_SexBody
# 変量の指定方法(以下は身長を指定する2通りの表記方法である)
Student24_SexBody$Height # 指定方法1
Student24_SexBody[,2] # 指定方法2
dim(Student24_SexBody) # 除外前のデータサイズ
summary(Student24_SexBody) # 除外前のデータの概観
# 欠損値を含むサンプルを除外
Student24_SexBody_noNA<-na.omit(Student24_SexBody)
Student24_SexBody_noNA
dim(Student24_SexBody_noNA) # 除外後のデータサイズ
summary(Student24_SexBody_noNA) # 除外後のデータの概観
## [演習4-1]
# 欠損値を含んだデータに対する相関行列の計算
cor(Student24_SexBody[,3:5]) # オプションを指定せず
cor(Student24_SexBody[,3:5],
use="pairwise.complete.obs") # 欠損値を含んでいる対を除外(計算方法1)
cor(Student24_SexBody[,3:5],
use="complete.obs") # 1変量でも欠損値を含んでいるサンプルはサンプル自身を除外(計算方法2)
# 欠損値を除外したデータに対する相関行列の計算
cor(Student24_SexBody_noNA[,3:5]) # オプションを指定せず
cor(Student24_SexBody_noNA[,3:5],
use="pairwise.complete.obs") # 欠損値を含んでいる対を除外(計算方法1)
cor(Student24_SexBody_noNA[,3:5],
use="complete.obs") # 1変量でも欠損値を含んでいるサンプルはサンプル自身を除外(計算方法2)
## 7.【問】回帰直線って何? ===> 次回
RresultTmp <- lm(Weight ~ Height, data=Student24)
tmpRand<-rnorm(2000)
StudTmp<-Student24
StudTmp$Height <-StudTmp$Height+tmpRand[1:772]*0.2
StudTmp$Weight <-StudTmp$Weight+tmpRand[1001:1772]*0.2
# 乱数で位置をずらした散布図
plot(StudTmp$Height, StudTmp$Weight,
xlab = "Height", ylab = "Weight",
main="Scatter Plot of Shintyou and Taijyuu")
abline(RresultTmp)
abline(h=seq(40,100,10), lty=3)
abline(v=seq(140,190,5), lty=3)