DS2403_1
Hayashi Atsuhiro
2024/10/17
0. 前回のアンケートを振り返って
- 講義は概ね適正な進行速度のようだ(一部難しく感じたとのご指摘もあり)が、追い付けなかったら、遠慮なく要求せよ。不明点は質問せよ。
- RStudioの使い方: 1行実行。複数行実行。Ctrl+Enter。
- 「コピペに終始」は避けてもらいたい。ソースコードを提供している理由は、皆さんの入力の手間を軽減するため。使い方の習得、関数の習得・指定方法に注力を。
- ユーザーが指定した変数名なのか、Rの関数名なのかが判りづらいかもしれない。それには慣れるしかないように思う。
- 演習問題は面倒がらずにこなし、何を目的とした演習なのかに思いを馳せてほしい。
-
(言い訳がましく聞こえるかも知れないが)講義資料は多めに作ってある。自習していただくのは大歓迎。
- 各自のデータについても、Excelを経由するのがお手軽であろう。
- データの入力ミスは無くせない。丁寧にチェックするしかない。ただ、頻度集計やクロス集計(今後紹介)を用いると発見し易くなる場合もある。
-
「漢字コードの取り扱い」を除いて、MacやLinuxも利用方法(関数等)は同じ。
-
【最終課題に関して】利用されるデータは大きいほど良い。多変量解析を行う場合は少なくとも30例、もしくは50例を超えないと面白味を感じられないと感じている。
-
【FYI】Web情報のExcelへの貼り付け方:
私はテキストエディタ(秀丸エディタ)に取り込んで、区切り部分にタブ文字(¥t)を挿入し、それをExcelに貼り込んでいる。他にも手法はあると思われる。例えば「Excel
Web データ
取り込み」ぐらいのワードで検索すると以下のようなサイトがヒットした。
- ディレクトリの構造理解。構造的なファイルの管理方法。
-
【補足情報】ディレクトリ関係
-
ディレクトリの移動方法: 一つ上の階層に戻るには「..」(ピリオド 2つ)を指定する。もしくは直接フルパスを指定して移動しても良い。
setwd("D:/home_sub3/R_Dir") # ホームディレクトリに移動(Set Working Directory) getwd() # 現在のディレクトリ位置を表示## [1] "D:/home_sub3/R_Dir"list.files() # ファイル・ディレクトリ一覧を表示## [1] "DNC_Tsuiseki" "DNC21" "Dragons" ## [4] "Food" "grain" "JEES" ## [7] "KougiDS20" "KougiDS21" "KougiDS22" ## [10] "KougiDS23" "KougiDS24" "LibraryInstall2211a.R" ## [13] "Misc" "NitechNSK21_R" "NitechNSK22_R" ## [16] "NitechNSK23_R" "plot1.png" "PresentationSample.Rmd" ## [19] "PresenTest.html" "PresenTest.Rmd" "R_Dir_NKK20" ## [22] "StatEdu24" "StatM20" "StatM21" ## [25] "StatM22" "StatM23" "Terao.zip" ## [28] "Terao_Lenovo" "Terao1" "Terao2" ## [31] "Unemployment" "確立楕円.R"setwd("KougiDS24") # ディレクトリを移動 getwd() # 現在のディレクトリ位置を表示## [1] "D:/home_sub3/R_Dir/KougiDS24"list.files() # ファイル・ディレクトリ一覧を表示## [1] "Dragons24.csv" "DS01_Questionnaire1.csv" ## [3] "DS01_Questionnaire2.csv" "DS01_Questionnaire3.csv" ## [5] "DS2402_1.pdf" "DS2402_1c.html" ## [7] "DS2402_1c.Rmd" "DS2402_2.pdf" ## [9] "DS2402_2a.html" "DS2402_2a.Rmd" ## [11] "DS2402_3.pdf" "DS2402_3b.html" ## [13] "DS2402_3b.Rmd" "DS2403_1.pdf" ## [15] "DS2403_1a.html" "DS2403_1a.Rmd" ## [17] "ExcelStudent24b.jpg" "Exp" ## [19] "lec01" "NewsPaper" ## [21] "OldFiles" "RStudio_Display.jpg" ## [23] "RStudio_Icon.jpg" "StockFiles" ## [25] "StudAll23b.csv" "StudAll24b.csv" ## [27] "新聞記事" "労働男女集約1_抽出2EUC.csv"setwd("..") # 一つ上のディレクトリに移動 getwd() # 現在のディレクトリ位置を表示## [1] "D:/home_sub3/R_Dir"list.files() # ファイル・ディレクトリ一覧を表示## [1] "DNC_Tsuiseki" "DNC21" "Dragons" ## [4] "Food" "grain" "JEES" ## [7] "KougiDS20" "KougiDS21" "KougiDS22" ## [10] "KougiDS23" "KougiDS24" "LibraryInstall2211a.R" ## [13] "Misc" "NitechNSK21_R" "NitechNSK22_R" ## [16] "NitechNSK23_R" "plot1.png" "PresentationSample.Rmd" ## [19] "PresenTest.html" "PresenTest.Rmd" "R_Dir_NKK20" ## [22] "StatEdu24" "StatM20" "StatM21" ## [25] "StatM22" "StatM23" "Terao.zip" ## [28] "Terao_Lenovo" "Terao1" "Terao2" ## [31] "Unemployment" "確立楕円.R"# もしくは、直接フルパスを指定する setwd("D:/home_sub3/R_Dir/KougiDS24") # 直接移動先を指定する getwd() # 現在のディレクトリ位置を表示## [1] "D:/home_sub3/R_Dir/KougiDS24"list.files() # ファイル・ディレクトリ一覧を表示## [1] "Dragons24.csv" "DS01_Questionnaire1.csv" ## [3] "DS01_Questionnaire2.csv" "DS01_Questionnaire3.csv" ## [5] "DS2402_1.pdf" "DS2402_1c.html" ## [7] "DS2402_1c.Rmd" "DS2402_2.pdf" ## [9] "DS2402_2a.html" "DS2402_2a.Rmd" ## [11] "DS2402_3.pdf" "DS2402_3b.html" ## [13] "DS2402_3b.Rmd" "DS2403_1.pdf" ## [15] "DS2403_1a.html" "DS2403_1a.Rmd" ## [17] "ExcelStudent24b.jpg" "Exp" ## [19] "lec01" "NewsPaper" ## [21] "OldFiles" "RStudio_Display.jpg" ## [23] "RStudio_Icon.jpg" "StockFiles" ## [25] "StudAll23b.csv" "StudAll24b.csv" ## [27] "新聞記事" "労働男女集約1_抽出2EUC.csv"
-
[先週の続き]
6.2. 視覚的表現: 樹葉図、ヒストグラム、箱ひげ図
6.3. 2次元のデータに対しては: 散布図、相関係数
7. プログラムの保存
1. 学生データを分析してみよう
先週はドラゴンズ選手の体格データを対象としたデータ分析の例を示した。 では、今度は皆さんから集めたデータ(過去分を含む)を分析してみよう。 実はドラゴンズ選手のデータには欠損値は含まれておらず、 「完全なデータ」(と呼ばれる)であったが、 実データでは往々にして欠損値を含んでいる(不完全なデータ)ことが多く、 例に漏れず学生データも欠損値を含んているのでその対応を含めて習得する。
[演習1-1] 学生データデータは「StudAll24b.xlsx」として、MoodleにExcel形式で掲載しておいた。各自でダウンロード後、先週の5.3節を参考に、CSV形式に変換せよ。
以下の例では、変換後のファイル名を「StudAll24b.csv」としたとして説明を行う。
そして、CSV形式に変換したファイルをRのディレクトリにコピーする。 Rのworking directory、もしくは各自の意図したディレクトリにコピーせよ。 以下の例では「D:/home_sub3/R_Dir/」の下の「KougiDS24」というディレクトリ (先週も利用した)にコピーしたとして説明を行う。つまり、 「D:/home_sub3/R_Dir/KougiDS24」に「StudAll24b.csv」をコピーしたものとして処理を例示するが、各自の設定に応じて読み替えてもらえば良い。
[Moodleに保存してあるファイル名] StudAll24b.xlsx
[CSV形式で保存されたファイル名] StudAll24b.csv (各自で別の名前を指定しても可。その場合はファイル名を忘れないように。)
[csvファイルを保存するディレクトリ名] D:/home_sub3/R_Dir/KougiDS24
- ここまでが完了したことを前提に以下の話を進めている。この演習を完璧に終えていないと先に進めないので解らない部分・疑問があるのであれば、早めに解決すべく連絡して助けを求めよ。
1.1. 学生データを読み込む
# ディレクトリの移動。必須ではない。個々人の設定に応じて。
setwd("D:/home_sub3/R_Dir") # ホームディレクトリに移動(Set Working Directory)
getwd() # 現在のディレクトリ位置を表示## [1] "D:/home_sub3/R_Dir"list.files() # ファイル・ディレクトリ一覧を表示## [1] "DNC_Tsuiseki" "DNC21" "Dragons"
## [4] "Food" "grain" "JEES"
## [7] "KougiDS20" "KougiDS21" "KougiDS22"
## [10] "KougiDS23" "KougiDS24" "LibraryInstall2211a.R"
## [13] "Misc" "NitechNSK21_R" "NitechNSK22_R"
## [16] "NitechNSK23_R" "plot1.png" "PresentationSample.Rmd"
## [19] "PresenTest.html" "PresenTest.Rmd" "R_Dir_NKK20"
## [22] "StatEdu24" "StatM20" "StatM21"
## [25] "StatM22" "StatM23" "Terao.zip"
## [28] "Terao_Lenovo" "Terao1" "Terao2"
## [31] "Unemployment" "確立楕円.R"setwd("KougiDS24") # ディレクトリを移動
list.files() # ファイル・ディレクトリ一覧を表示## [1] "Dragons24.csv" "DS01_Questionnaire1.csv"
## [3] "DS01_Questionnaire2.csv" "DS01_Questionnaire3.csv"
## [5] "DS2402_1.pdf" "DS2402_1c.html"
## [7] "DS2402_1c.Rmd" "DS2402_2.pdf"
## [9] "DS2402_2a.html" "DS2402_2a.Rmd"
## [11] "DS2402_3.pdf" "DS2402_3b.html"
## [13] "DS2402_3b.Rmd" "DS2403_1.pdf"
## [15] "DS2403_1a.html" "DS2403_1a.Rmd"
## [17] "ExcelStudent24b.jpg" "Exp"
## [19] "lec01" "NewsPaper"
## [21] "OldFiles" "RStudio_Display.jpg"
## [23] "RStudio_Icon.jpg" "StockFiles"
## [25] "StudAll23b.csv" "StudAll24b.csv"
## [27] "新聞記事" "労働男女集約1_抽出2EUC.csv"目的のファイル(StudAll24b.csv)が保存されていることが確認された。 では、このファイルからデータを読み込んでみよう。 その際、先頭部分(5行)には説明等の分析に必要ない情報が書き込まれて いるので、読み飛ばす(スキップ)。 また、それに続く行(6行目)には変数名(Header)が指定されているので「header=TRUE」を 指定する。Excel入力時にこの行を準備することをお薦めしたのは このように指定できるからである。
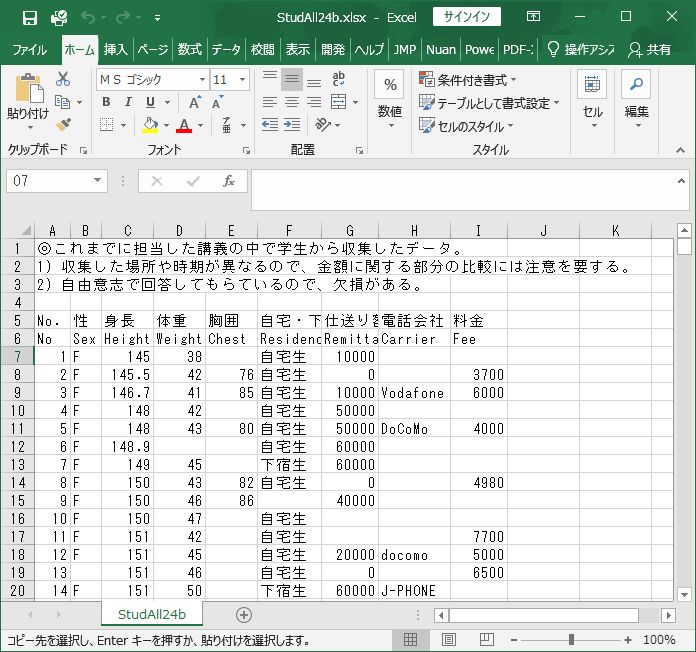
変数名(Header)の行を準備していない場合はシステム側が任意の変数名を 付けてくれるが、無味簡素な名称なので、意味が理解しやすい変数名を 自分で付ける方が効率が上がると考えている。 興味があるのなら、変数名が指定されていないデータを作成して 試してみるか、もしくは、上記のデータファイルに対して、6行目までを説明と捉えて、変数名の指定されていないファイルと捉えて読み込んでみれば理解が促進されるであろう。===> [演習1.1-1]
先週のドラゴンズデータには欠損値が含まれていなかったので、 何もオプションを指定しなかったが、 この学生データには欠損値が含まれているので、 そのことを明示的に示しておく。ここでは「空白(““)」が欠損値であることを指定している。 以下のデータ表示内ではそのことを示す「NA(No Answer, Not Available)」が散見されることを確認せよ。
# データの読み込み
Student24<-read.csv("StudAll24b.csv", skip=5, header=TRUE,
na.strings="", fileEncoding="utf8")ここで読み込んだデータを確認すべく
Student24を実行すると、
No Sex Height Weight Chest Residence Remittance Carrier Fee
1 1 F 145.0 38.0 NA 自宅生 10000 <NA> NA
2 2 F 145.5 42.0 76 自宅生 0 <NA> 3700
3 3 F 146.7 41.0 85 自宅生 10000 Vodafone 6000
<中略>
105 105 F 160.0 53.0 84 自宅生 25000 DoCoMo 3000
106 106 M 160.0 53.0 NA 自宅生 0 <NA> NA
107 107 M 160.0 55.0 NA 下宿生 65000 <NA> NA
108 108 M 160.0 55.0 NA 自宅生 0 <NA> 5500
109 109 M 160.0 55.0 NA 自宅生 25000 <NA> NA
110 110 M 160.0 55.0 NA 自宅生 30000 au 500
111 111 F 160.0 57.0 NA 自宅生 NA <NA> NA
[ reached 'max' / getOption("max.print") -- omitted 681 rows ]
データが表示される。意図通りに読み込めているであろうか? 目視でカラムズレ(横方向)等が起こっていないかを確認せよ。
しかし、最終行に何やらメッセージが表示される。 表示最大行数を超えたので表示を中止したことと、 表示し切れなかったサンプルが681件(行)あることを示している。 上の例では111行しかデータが表示されていない(正確にはConsoleペインの画面サイズにより中断される行数は変化する) ので、 今回のように行数(サンプル)が多いデータの場合は、 表示する最大行を大きく指定することにより 全部を表示させることができる。
# 表示行数の制限を解除
old.op <- options(max.print=999999)
Student24
No Sex Height Weight Chest Residence Remittance Carrier Fee
1 1 F 145.0 38.0 NA 自宅生 10000 <NA> NA
2 2 F 145.5 42.0 76 自宅生 0 <NA> 3700
3 3 F 146.7 41.0 85 自宅生 10000 Vodafone 6000
<中略>
775 775 F NA NA NA 自宅生 NA <NA> 4060
776 776 M NA NA NA 自宅生 NA <NA> NA
777 777 F NA NA NA 自宅生 NA <NA> NA
778 778 M NA NA NA <NA> NA Vodafone NA
779 779 M NA NA NA <NA> NA <NA> NA
780 780 M NA NA NA <NA> NA <NA> NA
781 781 F NA NA NA <NA> NA <NA> NA
782 782 <NA> NA NA NA <NA> NA <NA> NA
783 783 <NA> NA NA NA <NA> NA <NA> NA
784 784 <NA> NA NA NA <NA> NA <NA> NA
785 785 <NA> NA NA NA <NA> NA <NA> NA
786 786 <NA> NA NA NA <NA> NA <NA> NA
787 787 <NA> NA NA NA <NA> NA <NA> NA
788 788 <NA> NA NA NA <NA> NA <NA> NA
789 789 <NA> NA NA NA <NA> NA <NA> NA
790 790 M NA NA NA <NA> NA <NA> NA
791 791 <NA> NA NA NA <NA> NA <NA> NA
792 792 <NA> NA NA NA <NA> NA <NA> NA
しかし、一方で毎回、800行近くも表示されるのは面倒だと思えば、 上記のオプションに小さな数字を指定し直すか、 もしくは、以下で示すように陽に表示する行を指定する方法もある。 どちらの策を取るかは個人の好みに任せる。 とは言え、分析の初期段階では、全体を一度目視で確認しておくことも 必要であると考える。
# 先頭10人を表示
Student24[1:10,]## No Sex Height Weight Chest Residence Remittance Carrier Fee
## 1 1 F 145.0 38 NA 自宅生 10000 <NA> NA
## 2 2 F 145.5 42 76 自宅生 0 <NA> 3700
## 3 3 F 146.7 41 85 自宅生 10000 Vodafone 6000
## 4 4 F 148.0 42 NA 自宅生 50000 <NA> NA
## 5 5 F 148.0 43 80 自宅生 50000 DoCoMo 4000
## 6 6 F 148.9 NA NA 自宅生 60000 <NA> NA
## 7 7 F 149.0 45 NA 下宿生 60000 <NA> NA
## 8 8 F 150.0 43 82 自宅生 0 <NA> 4980
## 9 9 F 150.0 46 86 <NA> 40000 <NA> NA
## 10 10 F 150.0 47 NA 自宅生 NA <NA> NA# 先頭から数えて80番目から90番目の11人分を表示
Student24[80:90,]## No Sex Height Weight Chest Residence Remittance Carrier Fee
## 80 80 F 159 49 83 <NA> 80000 DoCoMo 12000
## 81 81 F 159 49 85 自宅生 0 DoCoMo 10000
## 82 82 F 159 49 88 自宅生 30000 <NA> NA
## 83 83 F 159 51 NA 自宅生 0 <NA> 6000
## 84 84 F 159 52 NA 自宅生 50000 <NA> NA
## 85 85 F 159 60 NA 下宿生 50000 <NA> 5000
## 86 86 <NA> 159 65 NA 自宅生 0 <NA> 11000
## 87 87 F 159 NA NA 下宿生 150000 <NA> NA
## 88 88 F 159 NA NA 自宅生 0 <NA> NA
## 89 89 F 159 NA NA 自宅生 0 <NA> 3700
## 90 90 F 159 NA NA 自宅生 0 <NA> 40000[演習1.1-1] 上記のデータファイルに対して、6行目までを説明と捉えて、変数名の指定されていないファイルと捉えて読み込んでみよ。どのような変数名がシステム側から付与されているか確認せよ。
# データの読み込み
Student24tmp1<-read.csv("StudAll24b.csv", skip=6, header=FALSE,
na.strings="", fileEncoding="utf8")
Student24tmp1[1:10,]
## V1 V2 V3 V4 V5 V6 V7 V8 V9
## 1 1 F 145.0 38 NA 自宅生 10000 <NA> NA
## 2 2 F 145.5 42 76 自宅生 0 <NA> 3700
## 3 3 F 146.7 41 85 自宅生 10000 Vodafone 6000
## 4 4 F 148.0 42 NA 自宅生 50000 <NA> NA
## 5 5 F 148.0 43 80 自宅生 50000 DoCoMo 4000
## 6 6 F 148.9 NA NA 自宅生 60000 <NA> NA
## 7 7 F 149.0 45 NA 下宿生 60000 <NA> NA
## 8 8 F 150.0 43 82 自宅生 0 <NA> 4980
## 9 9 F 150.0 46 86 <NA> 40000 <NA> NA
## 10 10 F 150.0 47 NA 自宅生 NA <NA> NA[演習1.1-2] 上記では、欠損値文字列が空白であることを明示的に指定した。このオプションを指定していなかったら(or 忘れた)とどのような結果になるか。
# データの読み込み
Student24tmp2<-read.csv("StudAll24b.csv", skip=5, header=TRUE,
fileEncoding="utf8")
Student24tmp2[1:10,]
## No Sex Height Weight Chest Residence Remittance Carrier Fee
## 1 1 F 145.0 38 NA 自宅生 10000 NA
## 2 2 F 145.5 42 76 自宅生 0 3700
## 3 3 F 146.7 41 85 自宅生 10000 Vodafone 6000
## 4 4 F 148.0 42 NA 自宅生 50000 NA
## 5 5 F 148.0 43 80 自宅生 50000 DoCoMo 4000
## 6 6 F 148.9 NA NA 自宅生 60000 NA
## 7 7 F 149.0 45 NA 下宿生 60000 NA
## 8 8 F 150.0 43 82 自宅生 0 4980
## 9 9 F 150.0 46 86 40000 NA
## 10 10 F 150.0 47 NA 自宅生 NA NA違いは判るであろうか? 一応解説しておくと、文字列変数(Sex, Residence, Carrier)のところの「<NA>」の有無が確認できるであろう。「na.strings=““」を指定せずに文字列を読み込むと、「長さ0の文字列」として認識される。
[演習1.1-3] 上記では、指定した番号の学生のデータを表示させた。では、指定した変量(例えば身長)だけを表示するにはどのように指定すれば良いか。
Student24[,3] # 身長だけを表示(指定方法1)
Student24$Height # 身長だけを表示(指定方法2)
[1] 145.0 145.5 146.7 148.0 148.0 148.9 149.0 150.0 150.0 150.0 151.0 151.0
[13] 151.0 151.0 151.0 151.7 152.0 152.0 152.0 152.0 153.0 153.0 153.0 153.0
[25] 153.0 153.0 153.0 153.0 153.0 153.5 154.0 154.4 155.0 155.0 155.0 155.0
[37] 155.0 155.0 155.0 156.0 156.0 156.0 156.0 156.0 156.0 156.0 156.0 156.0
[49] 156.0 156.0 156.0 156.0 156.0 156.0 156.5 156.5 157.0 157.0 157.0 157.0
<中略>
[721] 181.0 181.0 181.3 181.5 181.9 182.0 182.0 182.0 182.0 182.0 182.0 182.0
[733] 182.0 182.0 182.0 183.0 183.0 183.0 183.0 183.0 183.0 184.0 184.0 185.0
[745] 185.0 185.0 185.0 185.0 186.0 186.5 187.0 NA NA NA NA NA
[757] NA NA NA NA NA NA NA NA NA NA NA NA
[769] NA NA NA NA NA NA NA NA NA NA NA NA
[781] NA NA NA NA NA NA NA NA NA NA NA NA
[演習1.1-4] 上記に加えて、指定した学生(例えば13番目から20番目まで)の、指定した変量(例えば身長)だけを表示するにはどのように指定すれば良いか。
Student24[13:20,3] # 13番目から20番目まで身長だけを表示(指定方法1)
Student24$Height[13:20] # 13番目から20番目まで身長だけを表示(指定方法2)
## [1] 151.0 151.0 151.0 151.7 152.0 152.0 152.0 152.0[演習1.1-5] 更に上記に加えて、指定した学生(例えば13番目から20番目まで)の、指定した複数の変量(例えば身長と体重、胸囲)だけを表示するにはどのように指定すれば良いか。
Student24[13:20,3:5] # 13番目から20番目まで身長と体重、胸囲だけを表示(指定方法1)
Student24[13:20,c(3,4,5)] # 13番目から20番目まで身長と体重、胸囲だけを表示(指定方法2)
## Height Weight Chest
## 13 151.0 46.0 NA
## 14 151.0 50.0 NA
## 15 151.0 NA NA
## 16 151.7 41.5 80
## 17 152.0 35.0 77
## 18 152.0 43.0 NA
## 19 152.0 44.0 NA
## 20 152.0 45.0 NA[演習1.1-6] では、指定した学生(例えば13番目から20番目まで)の、指定した複数の変量(例えば身長と胸囲)だけを表示するにはどのように指定すれば良いか。
Student24[13:20,c(3,5)] # 13番目から20番目まで身長と胸囲だけを表示
## Height Chest
## 13 151.0 NA
## 14 151.0 NA
## 15 151.0 NA
## 16 151.7 80
## 17 152.0 77
## 18 152.0 NA
## 19 152.0 NA
## 20 152.0 NA[演習1.1-7] では、指定した学生(例えば13番目から20番目まで)の、指定した複数の変量(例えば胸囲と身長)だけを表示するにはどのように指定すれば良いか。
Student24[13:20,c(5,3)] # 13番目から20番目まで胸囲と身長だけを表示
## Chest Height
## 13 NA 151.0
## 14 NA 151.0
## 15 NA 151.0
## 16 80 151.7
## 17 77 152.0
## 18 NA 152.0
## 19 NA 152.0
## 20 NA 152.01.2. 学生データの概観を把握する
まずは読み込んだデータを概観してみよう。 データのサイズ、変量数、変量名を表示するには?
# 基本情報を概観してみる
dim(Student24) # データサイズを表示(dimension)## [1] 792 9colnames(Student24) # 変数名の一覧(column names)## [1] "No" "Sex" "Height" "Weight" "Chest"
## [6] "Residence" "Remittance" "Carrier" "Fee"データのサイズや変数名が把握できたであろうか? 772人、9変量のデータであることが判る。 変量名もExcelで指定されたものが採用されていることが判る。
次に各変量の概要を見てみよう。
# 基本情報を概観してみる
str(Student24) # データの内容を情報付きで表示(structure)## 'data.frame': 792 obs. of 9 variables:
## $ No : int 1 2 3 4 5 6 7 8 9 10 ...
## $ Sex : chr "F" "F" "F" "F" ...
## $ Height : num 145 146 147 148 148 ...
## $ Weight : num 38 42 41 42 43 NA 45 43 46 47 ...
## $ Chest : num NA 76 85 NA 80 NA NA 82 86 NA ...
## $ Residence : chr "自宅生" "自宅生" "自宅生" "自宅生" ...
## $ Remittance: int 10000 0 10000 50000 50000 60000 60000 0 40000 NA ...
## $ Carrier : chr NA NA "Vodafone" NA ...
## $ Fee : int NA 3700 6000 NA 4000 NA NA 4980 NA NA ...各変量はそれぞれ、文字型(chr, character)か数字型(num, number)か 整数値(int, integer)かが判る。 数値型の内、特に整数値を取るものが整数型として扱われる。 右側には実際のデータが例示されている
# 基本情報を概観してみる
summary(Student24) # データの要約を表示## No Sex Height Weight
## Min. : 1.0 Length:792 Min. :145.0 Min. : 35.00
## 1st Qu.:198.8 Class :character 1st Qu.:164.0 1st Qu.: 53.38
## Median :396.5 Mode :character Median :170.0 Median : 60.00
## Mean :396.5 Mean :168.9 Mean : 59.93
## 3rd Qu.:594.2 3rd Qu.:175.0 3rd Qu.: 65.00
## Max. :792.0 Max. :187.0 Max. :100.00
## NA's :41 NA's :100
## Chest Residence Remittance Carrier
## Min. : 30.50 Length:792 Min. : 0 Length:792
## 1st Qu.: 82.25 Class :character 1st Qu.: 0 Class :character
## Median : 87.00 Mode :character Median : 20000 Mode :character
## Mean : 86.08 Mean : 35523
## 3rd Qu.: 90.00 3rd Qu.: 50000
## Max. :112.00 Max. :350000
## NA's :550 NA's :154
## Fee
## Min. : 0
## 1st Qu.: 3000
## Median : 4380
## Mean : 5370
## 3rd Qu.: 7000
## Max. :40000
## NA's :376各変量の大まかな様子が判るであろうか? 文字変量(character)の場合はそのことが、 また数値変量の場合は、最大値や平均値等、加えて欠損値の個数も 表示されている。
2. 基礎統計: 欠損値を含む場合 【今週の本題】
では、この中から身長に注目して基礎統計を進めてみよう。 まずは概観するために「summary」で身長だけを見てみる。
summary(Student24$Height) # 前項の出力の身長部分のみ。欠損値の個数も表示される。## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 145.0 164.0 170.0 168.9 175.0 187.0 41この結果から判るように、身長には40例の欠損値(NA)が含まれている。 そこで、身長の平均値や標準偏差を求めてみよう。それぞれの関数は既に教えたので…
mean(Student24$Height) # 平均値## [1] NAsd(Student24$Height) # 標準偏差## [1] NAどちらも「NA」と返答され、残念ながらうまく計算してくれないことが判る。 今回のように欠損値を含んだデータの場合は、そのままでは計算できず、 欠損値を除外して計算する必要がある。 そのためには、欠損値の除外を指示するオプションとして 「na.rm=TRUE」を指定する必要がある(NA removeの意味)。
「na.rm」は真偽の二値の何れかを指定するオプションで、 デフォルト(指定なし)では偽(FALSE)となっており欠損値を除外しない。 以下では真(TRUE)、つまり欠損値を計算対象から除外(No Answer Remove) することを指定していることになる。「TRUE」と4文字で指定しているが 省略形として「T」でも構わない。同様に偽は「FALSE」もしくは「F」である。
mean(Student24$Height, na.rm=TRUE) # 平均値## [1] 168.8782sd(Student24$Height, na.rm=TRUE) # 標準偏差## [1] 7.756683var(Student24$Height, na.rm=T) # 分散## [1] 60.16614quantile(Student24$Height, na.rm=T) # 四分位数## 0% 25% 50% 75% 100%
## 145 164 170 175 187[演習2-1] 上記では欠損値を除外するオプションとして「na.rm = TRUE」を指定した。何も指定しないと「偽(FALSE)」となると説明したが、実際に試してみよ。
mean(Student24$Height, na.rm=FALSE) # 平均値## [1] NAsd(Student24$Height, na.rm=F) # 標準偏差## [1] NA3. 視覚的把握
先週既に取り上げたので詳細の説明は不要であろう。 グラフに任意の説明(ラベル)を加えたい場合の書式を紹介しておく。
hist(Student24$Height, right=FALSE, main="Histgram of Shintyou") # ヒストグラム
abline(h=seq(0,200,25), lty=3)
好みの領域、好みの形式のヒストグラムを描画するにはいくつかオプションを指定すれば良い。それぞれの指定値がどのように反映されているか確認せよ。
hist(Student24$Height, right=FALSE,
main="Histgram of Shintyou with some options",
breaks=seq(140,195,2.5),
xlim= c(100, 200), ylim=c(0,150)) # ヒストグラム
abline(h=seq(0,175,20), lty=3)
boxplot(Student24$Height, main="boxplot of Shintyou") # 箱ひげ図
abline(h=seq(150,180,10), lty=3)
横方向に伸びる箱ひげ図。
boxplot(Student24$Height, horizontal=TRUE, main="boxplot of Shintyou") # 箱ひげ図(横向き)
abline(v=seq(150,180,10), lty=3)
横軸に身長、縦軸に体重を取った散布図。
plot(Student24$Height, Student24$Weight, main="Scatter Plot of Shintyou and Weight") # 散布図
abline(h=seq(40,100,10), lty=3)
abline(v=seq(150,180,10), lty=3)
縦軸と横軸を入れ替えた散布図。用いているデータも表している情報も同じだが印象は同じであろうか?
plot(Student24$Weight, Student24$Height, main="Scatter Plot of Weight and Shintyou") # 散布図
abline(h=seq(150,180,10), lty=3)
abline(v=seq(40,100,10), lty=3)
【発展】
プロット点を(乱数を用いて)微妙に揺らして描画すると密度が視覚的に理解できる。
plot(Student24$Height+0.25*rnorm(1000),
Student24$Weight+0.25*rnorm(1000),
main="Scatter Plot of Shintyou and Weight with small noise") # 密度が感じられる散布図
abline(h=seq(40,100,10), lty=3)
abline(v=seq(150,180,10), lty=3)
- 相関係数(2変量間の関係度合いを示す指標。-1~1で度合いを示す)
cor(Student24$Weight, Student24$Height) # 相関係数## [1] NA欠損値を含むデータの場合、計算できないと警告を表示してくる。 そこで、「完全データのみ」を使った相関係数を計算させる。
cor(Student24$Weight, Student24$Height, use = "complete.obs") # 完全データに対する相関係数## [1] 0.6514913- ホームディレクトリに戻しておく。(必須ではない)
setwd("D:/home_sub3/R_Dir") # ホームディレクトリに移動(Set Working Directory)[演習3-1] ヒストグラムのところで紹介したxlim(横軸側), ylim(縦軸側)は他の描画用関数でも利用可能である。ヒストグラムも含めて、各パラメータを陽に指定してみて、自分の好みの形式のグラフを作成してみよ。
【思い】Rには統計分析に有益な関数が準備されているので、それらを駆使して分析ができるようになってほしい。
4. プログラムの保存
先週と同様に、苦労して作成したプログラムなので保存しておこう。 RStudio画面の左上にある[File]-[Save] もしくは[Save As]と進んで 自分の希望の場所(ディレクトリ)に希望の名称(ファイル名)で保存せよ。 なお、ファイルの属性には「.R」が付けられる。 また、保存したプログラムは[File]-[Open File]で呼び出すことができる。
[演習4-1] 各自のプログラムに好みのファイル名を付けて保存せよ。
[例] StudAll24b.R
[演習4-2: 今週全体を通して] ここまで身長に注目していくつかの指標を調べてきた。残りの連続変量(体重、胸囲、小遣い額、スマホ利用額)についても各自で調べてみよ。
5. レポートの作成方法
各種の統計手法を用いて分析を終えたら、それらを報告書やレポートにまとめる必要がある。RStudioには便利な機能(※)が付随しているのだが、
その使い方も含めて説明を始めると本講義の本来のゴールに
たどり着けなくなるので、 ここでは簡便で直感的な方法を紹介しておく。
その方法は、MS
Wordの新規の文書ファイルを準備し、各種計算結果をそこにコピー&ペーストして行くことで最低限の文書ファイルを作成することである。
その際、コピーする情報が、文字情報かグラフ情報かによってコピー元のペインが異なる。
- 文字情報: Consoleペインに表示された結果を選択後、
右クリックを押すとウインドウが現れるので、 その中の「Copy」を選択し、MS
Wordの方に移動して、
「貼り付け」のオプションから「形式を選択して貼り付け」を選び「テキスト」を実行する。
- コピー対象の例: データのサイズ、平均値、標準偏差、分散、四分位数等
- グラフ情報: Plotsペインに表示されたグラフの上で
右クリックを押すとウインドウが現れるので、 その中の「Copy
image」を選択し、MS Wordの方に移動して、
「貼り付け」のオプションから「形式を選択して貼り付け」を選び「ビットマップ(DIB)」を実行する。
- コピー対象の例: ヒストグラム、箱ひげ図、散布図等
情報をMS Wordに貼り付けた後は、それらの前後に「調査目的」や 「判ったこと」、「考察」等を記入していく。
(※) 興味がある者は「R Markdown」で検索して調べてみよ。
【思い】欠損値を含むデータの分析方法と、レポートの作成方法を修得してほしい。
【分析例】
学生データの中から身長に関して分析を行った。
792名中、41件の欠損値があったので、分析対象となったのは751名(=792-41)である。
この751名の身長についての各種の基礎統計量を算出した。以下はその要約である。
平均 168.9
標準偏差 7.8
分散 60.2
最小値 145.0
最大値 187.0
中央値 170.0
第1四分位数 164.0
第3四分位数 175.0
<図省略>
図1. 身長のヒストグラム
<図省略>
図2. 身長の箱ひげ図
このヒストグラムや箱ひげ図を見ると、
身長はやや大きい方(右側)に偏った分布をしていることが判る。
また、箱ひげ図から、下側に外れ値に該当すると思われるサンプルが存在する。
<<その他気付いたことを記載していく>>。
これらの根拠となったRの出力は以下の通りである。
> summary(Student24$Height)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
145.0 164.0 170.0 168.9 175.0 187.0 41
> sd(Student24$Height, na.rm=TRUE)
[1] 7.756683
> var(Student24$Height, na.rm=TRUE)
[1] 60.16614
81. 参考
このページで取り扱ったプログラムだけを抜き出して以下に列挙しておく。
## 1.1. 学生データを読み込む
# ディレクトリの移動。必須ではない。個々人の設定に応じて。
setwd("D:/home_sub3/R_Dir") # ホームディレクトリに移動(Set Working Directory)
getwd() # 現在のディレクトリ位置を表示
list.files() # ファイル・ディレクトリ一覧を表示
setwd("KougiDS24") # ディレクトリを移動
list.files() # ファイル・ディレクトリ一覧を表示
# データの読み込み
Student24<-read.csv("StudAll24b.csv", skip=5, header=TRUE,
na.strings="", fileEncoding="utf8")
Student24
# 表示行数の制限を解除
old.op <- options(max.print=999999)
Student24
# 先頭10人を表示
Student24[1:10,]
# 先頭から数えて80番目から90番目の11人分を表示
Student24[80:90,]
# [演習1.1-1]
# データの読み込み
Student24tmp1<-read.csv("StudAll24b.csv", skip=6, header=FALSE,
na.strings="", fileEncoding="utf8")
Student24tmp1[1:10,]
# [演習1.1-2]
# データの読み込み
Student24tmp2<-read.csv("StudAll24b.csv", skip=5, header=TRUE,
fileEncoding="utf8")
Student24tmp2[1:10,]
# [演習1.1-3]
Student24[,3] # 身長だけを表示(指定方法1)
Student24$Height # 身長だけを表示(指定方法2)
# [演習1.1-4]
Student24[13:20,3] # 13番目から20番目まで身長だけを表示(指定方法1)
Student24$Height[13:20] # 13番目から20番目まで身長だけを表示(指定方法2)
# [演習1.1-5]
Student24[13:20,3:5] # 13番目から20番目まで身長と体重、胸囲だけを表示(指定方法1)
Student24[13:20,c(3,4,5)] # 13番目から20番目まで身長と体重、胸囲だけを表示(指定方法2)
# [演習1.1-6]
Student24[13:20,c(3,5)] # 13番目から20番目まで身長と胸囲だけを表示
# [演習1.1-7]
Student24[13:20,c(5,3)] # 13番目から20番目まで胸囲と身長だけを表示
## 1.2. 学生データの概観を把握する
# 基本情報を概観してみる
dim(Student24) # データサイズを表示(dimension)
colnames(Student24) # 変数名の一覧(column names)
# 基本情報を概観してみる
str(Student24) # データの内容を情報付きで表示
# 基本情報を概観してみる
summary(Student24) # データの要約を表示
## 2. 基礎統計: 欠損値を含む場合
summary(Student24$Height) # 前項の出力の身長部分のみ。欠損値の個数も表示される。
mean(Student24$Height) # 平均値
sd(Student24$Height) # 標準偏差
mean(Student24$Height, na.rm=TRUE) # 平均値
sd(Student24$Height, na.rm=TRUE) # 標準偏差
var(Student24$Height, na.rm=T) # 分散
quantile(Student24$Height, na.rm=T) # 四分位数
mean(Student24$Height, na.rm=FALSE) # 平均値
sd(Student24$Height, na.rm=F) # 標準偏差
## 3. 視覚的把握
hist(Student24$Height, right=FALSE, main="Histgram of Shintyou") # ヒストグラム
abline(h=seq(0,200,25), lty=3)
hist(Student24$Height, right=FALSE,
main="Histgram of Shintyou with some options",
breaks=seq(140,195,2.5),
xlim= c(100, 200), ylim=c(0,150)) # ヒストグラム
abline(h=seq(0,175,20), lty=3)
boxplot(Student24$Height, main="boxplot of Shintyou") # 箱ひげ図
abline(h=seq(150,180,10), lty=3)
boxplot(Student24$Height, horizontal=TRUE, main="boxplot of Shintyou") # 箱ひげ図(横向き)
abline(v=seq(150,180,10), lty=3)
plot(Student24$Height, Student24$Weight, main="Scatter Plot of Shintyou and Weight") # 散布図
abline(h=seq(40,100,10), lty=3)
abline(v=seq(150,180,10), lty=3)
plot(Student24$Weight, Student24$Height, main="Scatter Plot of Weight and Shintyou") # 散布図
abline(h=seq(150,180,10), lty=3)
abline(v=seq(40,100,10), lty=3)
plot(Student24$Height+0.25*rnorm(1000),
Student24$Weight+0.25*rnorm(1000),
main="Scatter Plot of Shintyou and Weight with small noise") # 密度が感じられる散布図
abline(h=seq(40,100,10), lty=3)
abline(v=seq(150,180,10), lty=3)
cor(Student24$Weight, Student24$Height) # 相関係数
cor(Student24$Weight, Student24$Height, use = "complete.obs") # 完全データに対する相関係数
setwd("D:/home_sub3/R_Dir") # ホームディレクトリに移動(Set Working Directory)