DS2401_2
Hayashi Atsuhiro
2024/10/03
経営システム分野 3年後期 (7712)
データサイエンス(前半)、担当:
林
木曜日 3-4限(10:30-12:00)@21号館 2139講義室
多変量解析 ~ RとRStudioを用いて ~
@11号館 5階 516室
hayashi.atsuhiro@nitech.ac.jp
052-735-5119 (内線 5119)
講義「データサイエンス」(前半、10/3-11/14)
- [本講義の目指すところ] 多変量解析に関するモデルの考え方を理解する。
① データサイエンス(Data Science, DS)とは?
②
RやRStudioの有用性、インストール
③ 簡単な統計、データの読み込み
④ 集計、頻度、ヒストグラム、散布図、散布図行列
⑤ 重回帰分析
⑥
主成分分析、因子分析
⑦ レポート課題作成・提出
0. 講義の進め方について
-
提示資料はMoodleに掲載: HTML(HyperText Markup Language) &
PDFの2種類で保存しておくが内容は同一。紙での配布は考えていませんが、ご希望がありますか?
- 持参し忘れたら
- 欠席したら
- 後日見てみたくなったら
- 各種連絡もMoodleに掲載する
-
当日朝までには掲載するようにします。
なお、確定後に記載内容に修正があった場合には、掲載済みのものに加筆・修正するのではなく新版を追加で掲載するようにします。
-
各自の持参PCで試行することをおすすめするが、教育用端末でも利用可能。
- 連絡先 e-mail アドレス : hayashi.atsuhiro@nitech.ac.jp
- 研究室 : 11号館 5階 516室
- オフィスアワー : 研究室に在席していれば対応可能です。事前に電子メールで予定をお尋ねいただければ最大限対応します。
1. データサイエンス(Data Science, DS)とは?
-
Data Science, DS
-
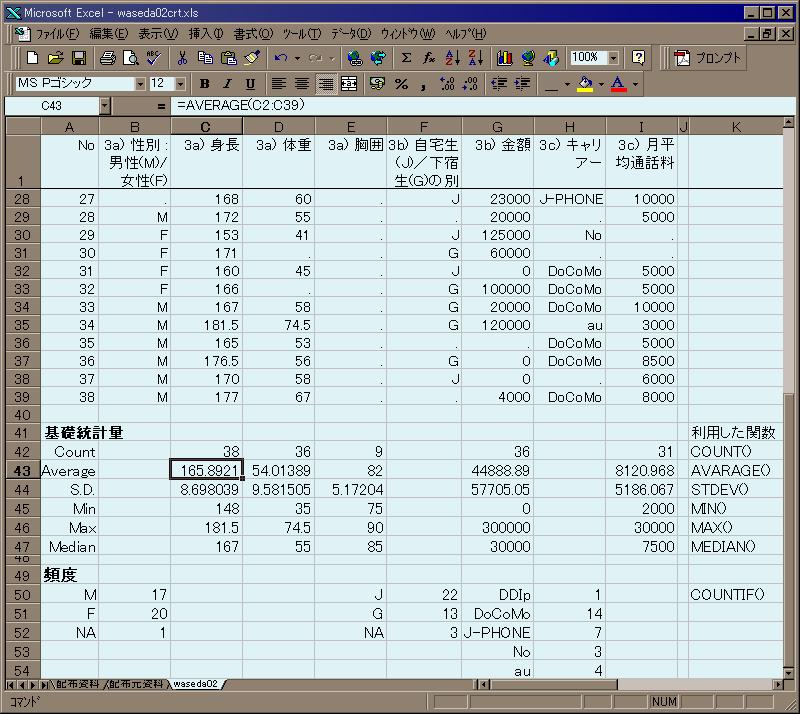
皆さんのイメージは?

-
「データサイエンティスト」を目指しておられる方もいらっしゃるかもしれませんね。
-
我々は何故データを集めるのでしょうか?
-
2020年(R2)秋に実施された「国勢調査」は何のため? 何で必要? 回答義務があることをご存知でしたか? 次回(2025年(R7)、5年毎)も是非提出してくださいね。 . .
- 【参考】令和2年国勢調査: 総務省統計局
- 【分析結果】 『都心に潜む限界集落 「一人勝ち」の東京、ひとごとでない高齢化の波』 . : 朝日新聞 2022年10月11日
-
皆さんのイメージは?
-
「データ」を扱う学問としての統計学
- 情報処理、データマイニング、データサイエンス
- いろいろな手法、モデルがある
- データ群の根底に内在する 構造(モデル)を明らかに
-
他にも
- 観察力、探究心、倫理観、…
- 広い知識、経験、…

2. 統計解析に必要なもの
-
データを“良く・深く知ろう”とする気持ち
- データに対する思い入れ
- 日頃の観察力から育成できるものか?
-
統計手法の修得: 基礎統計量、多変量解析、実験計画法等、…
-
統計ソフトウェア: 道具
- Excelではダメなの?
- 基礎集計 by Excel(表計算ソフト)
- 大量データになったら?
- 複雑な統計手法になったら? 多変量解析…
- 欠損値の取り扱い
-
統計向けソフトウエアの利用が一般的 : データ解析
- BMDP : BioMedical Programs
- SPSS : Statistical Package for Social Science
- SAS : Statistical Analysis System
- S, S-PLUS : Statistical
- R : Sから派生したフリーソフト+便利ツール
- LISP-STAT : Lisp で実現、フリーソフト
- Statistica
- SAS JMP Pro 17.2 <=== ソフトウェアライセンス提供サービス( https://www.cc.nitech.ac.jp/service/common/license.html)
- Python
- …
 計算
計算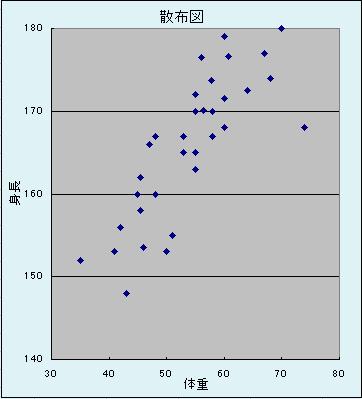 図示
図示3. RとRStudioの魅力
- R: 統計解析用の計算機言語
- RStudio: Rの利用を支援する統合開発環境
- 共にフリー(無料)である
- たくさんの開発者が支えている
- 便利ツールも多い
-
本講義ではRとRStudioを使う
- 実際には、RStudioを通してRを使っているのだが、両者を区別して意識することはないであろう。
-
各自のPCにインストールして利用する方が利便性が高いのではないか?
- Windows、Mac、Linuxの何れでも利用可能
- 学内の教育用端末にもインストールされている。 なお、ディレクトリ名に漢字を使わないようにとの注意あり。
4. RとRStudioのインストール
4.1 ディレクトリとその利用方法
(Rに限らないが)コンピュータで取扱う文書ファイルやデータファイル、 プログラムファイル等を大量に保存する際に、 利用目的ごとにディレクトリ(フォルダと呼ぶと理解できるのかも)を作成して、 それぞれに分類すべく、階層的な構造で保存しておくことで 素早く目的のファイルを見つける・アクセスすることができる。 想像だが、皆さんもMS WordファイルやPDFファイル等を講義ごとや イベントごとのディレクトリに分類して利活用しているのではないか?
Rでのファイルの利用も同様であり、利用目的(中日ドラゴンズデータとか学生データとか)に 合わせてディレクトリを作成し、それぞれに関連したRプログラムやデータを それぞれに保存しておくと素早く探し出すことができる。 また、Rプログラム内からデータファイルを参照する際にも ディレクトリ名を含んだ長ったらしいファイル名を指定することも回避できる。
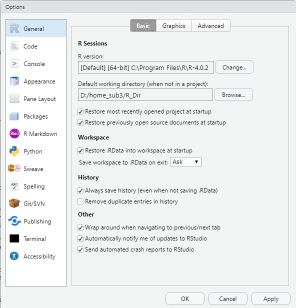
そこで、Rの利用に際して、利用のベース(基本場所)となるディレクトリを予め決めておき、 そこからの相対的位置でファイルを指定することで、参照方法が簡便になる。 このベースとなるディレクトリのことをRでは「Default working directory」 と呼んでおり、 RStudioの設定で指定しておくと起動時にそこに位置付けて利用できる。
参考までに、私の場合は、Dドライブにあるディレクトリ「home_sub3」 の下に、「R_Dir」というディレクトリを作成して、 ここをベース(基本場所)に利用しているが、 Dドライブである必要はなく、ディレクトリ名も自由に指定してもらって構わない。 ただし、トラブルを避けるために、ディレクトリ名やファイル名には漢字を用いず、半角英数字だけで指定するようにしてもらいたい。
つまり、インストールする前に- R用のディレクトリを決める。(私の例では”D:/home_sub3/R_Dir”)
- そのためのディレクトリを作成する。
- そのディレクトリをRStudioの設定で指定する(後述)。
という作業が必要になる。
4.2 インストール作業
- ここではWindowsを例に説明するが、MacやLinuxでも同じ環境を手に入れることができる。
-
以下のWebに作業手順が丁寧に説明されているので、これを利用させてもらうことにする。
- 「R初心者の館(RとRStudioのインストール、初期設定、基本的な記法など)」
- https://das-kino.hatenablog.com/entry/2019/11/07/125044
- 「RとRStudioのインストール」
- 「RStudioの初期設定」
-
【参考】現時点での最新版は以下の通りであった(10月01日現在)
- R-4.4.1 for Windows (https://cran.rstudio.com/, https://cran.rstudio.com/bin/windows/base/)
- RStudio-2024.09.0-375.exe (RStudio Desktop) (https://www.rstudio.com/products/rstudio/download/)
-
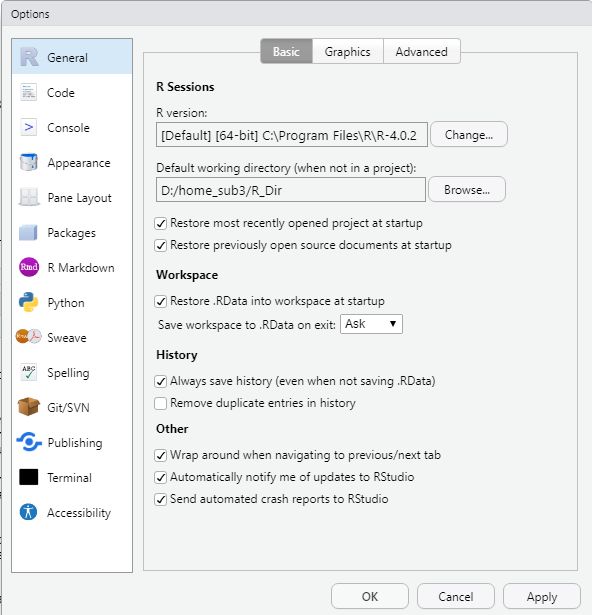
【注意喚起】上記「R初心者の館」で説明されている事項は、基本的にはRとRStudioをダウンロード後に、PCにインストールする作業であるが、2番目の節「RStudioの初期設定」を忘れがちである。具体的には「Tools」-「Global
Options」の中で行う
以下の4つに節に説明のある事項を忘れないようにしてもらいたい。
- デフォルトの作業ディレクトリ(Working Directory)の設定
- 文字コードの設定
- ”見栄え”の設定 ===>【注】RStudio themeに「Classic」がないので「Modern」を選択する
- パッケージをダウンロードするCRANリポジトリの設定 ===>【注】山形大学のサイトを選択する
-
【私の例】本講義では、以下の指定を行ったとして説明を続けるが、
Dドライブである必要はなく、ディレクトリ名も好みに合わせて自由に指定してもらって構わない。
- ドライブ名: Dドライブ
- ディレクトリ名: /home_sub3/R_Dir
- 【蛇足】Linuxへのインストール
5. 起動方法、インストールできたかの確認
-
RStudioの起動
- スタートメニューから「RStudio」→「RStudio」
- または、デスクトップに表示されているrstudioのアイコン(右図)をクリックしてRStudioを起動する
-
RはRStudio内から操作されるので陽に意識する必要はない
- なお、インストール直後の初回だけ、以下のウインドウが表示され、 RStudio内から起動するRのバージョンを指定する必要がある。 自動で認識してくれるので、単に「OK」をクリックして先に進めば良い。
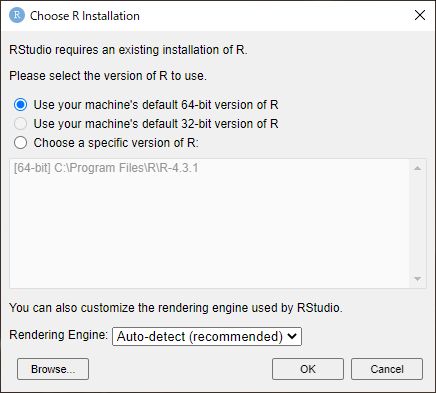
-
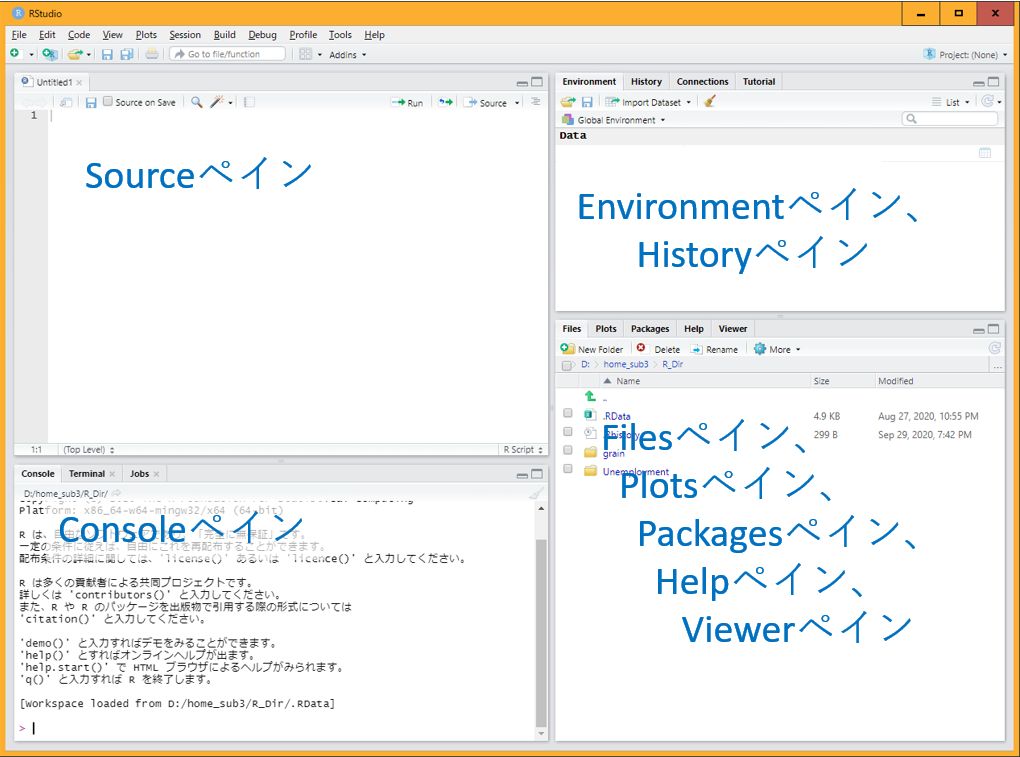
画面の説明: 4つの画面がありそれぞれに役割あり
- 左上: Sourceペイン <=== プログラムを入力する
- 左下: Consoleペイン <=== 計算結果が表示される
- 右上: Environmentペイン、Historyペイン
- 右下: Filesペイン、Plotsペイン、Packagesペイン、 Helpペイン、Viewerペイン
- [補足1] 初回起動時には「Enable Automated Crash Reporting」というアラートウインドウが表示されるが、バグレポートに協力するか否かを問うているので、ご自身で判断いただいて先に進んでください(Yes/No)。
- [補足2] ConsoleペインにはインストールしたRのバージョンが表示されているはずである。今回の例で言えば「R version 4.4.1」と表示されているのではないか。
- [補足3] ペインが3つしか表示されておらずSourceペインが1行しか表示されていなかったら、Consoleペインの右上部(バー右端)をクリックする。
- 手始めに簡単な操作を行ってみる
-
Sourceペイン(左上の領域)で
- 「3+5」と入力後、「Ctrl+Enter」(Ctrlキーを押しながら、Enterキーを押す)を行うと、Consoleペインに「8」と計算結果が出力される。
- 「5^3」と入力後、「Ctrl+Enter」を行うと、Consoleペインに「125」と計算結果が出力される。
- 演算記号: 四則演算(+、ー、*、/)、べき乗: ^、剰余: %%、平方根: sqrt()
3+5 # 加算## [1] 85^3 # べき乗## [1] 125sqrt(5) # 平方根## [1] 2.236068【補足】以後、資料中の、灰色の囲みエリアは、Sourceペインでの利用者の入力画面を示し、白い囲みエリアはConsoleペインのシステムからの計算結果画面を示す。 また「#」(半角)マークより右側は利用者への説明のためのコメントであり、計算には影響しない。
[演習5-1] 上記演算子を用いて各自で任意の計算を行ってみよ。
- 電卓のような使い方。より複雑な利用方法は後述。
任意の「式を入力」後、「Ctrl+Enter」で実行する。
【補足】教室端末での利用時の注意
-
教室端末にインストールされているバージョンは以下のもののようである。
起動時に「より最新のバージョンが存在すること」のアラートが表示されるが、
「Ignore Update」で無視すれば良い(無視するしかない)。
- R: R-4.2.2
- RStudio: RStudio-2022-12.0+353
-
OSがWindows11であり、RStudioを起動させる方法としては、
画面最下段のウインドウマークをクリックし、表示された画面の右上(以下画面1)の「すべてのアプリ>」をクリックする。すると、アプリの一覧が表示されるので、その中から「RStudio」を選択する。
-
いちいちこの作業をするのが面倒であれば、以下の何れかの方法で対処することができる。
- RStudioの起動アイコン(ショートカット)をディスクトップにコピーして、そこから起動する。
- RStudioをスタートにピン留めして、そこから起動する。
- RStudioをタスクバーにピン留めして、そこから起動する。
-
Default working directory(後述)には、OneDriveが指定されているが、
その部分は変更しないように。また、上にも示したが、トラブルを避けるために、ディレクトリ名やファイル名には漢字を用いず、半角英数字だけで指定するようにしてもらいたい。私の例では以下を指定している(以下画面2)。なお、「fml08307」は私のIDである。
- C:/Users/fml08307/OneDrive - NITech/R_Dir
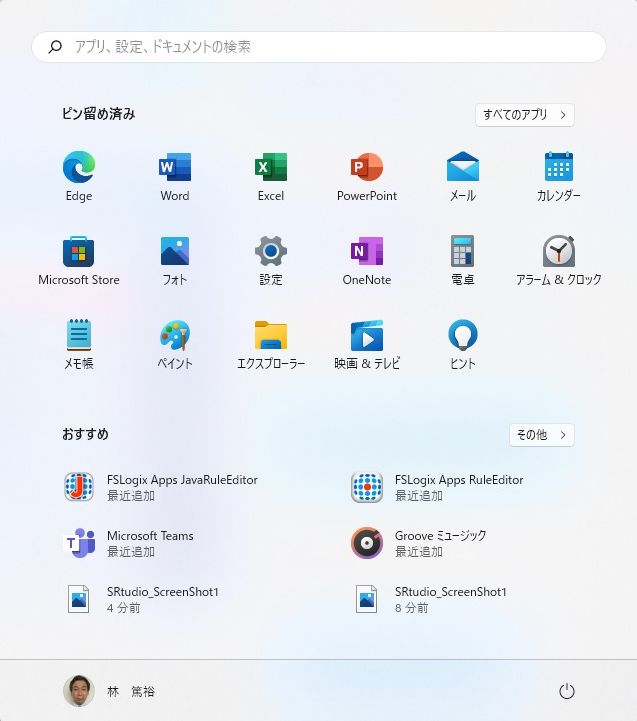
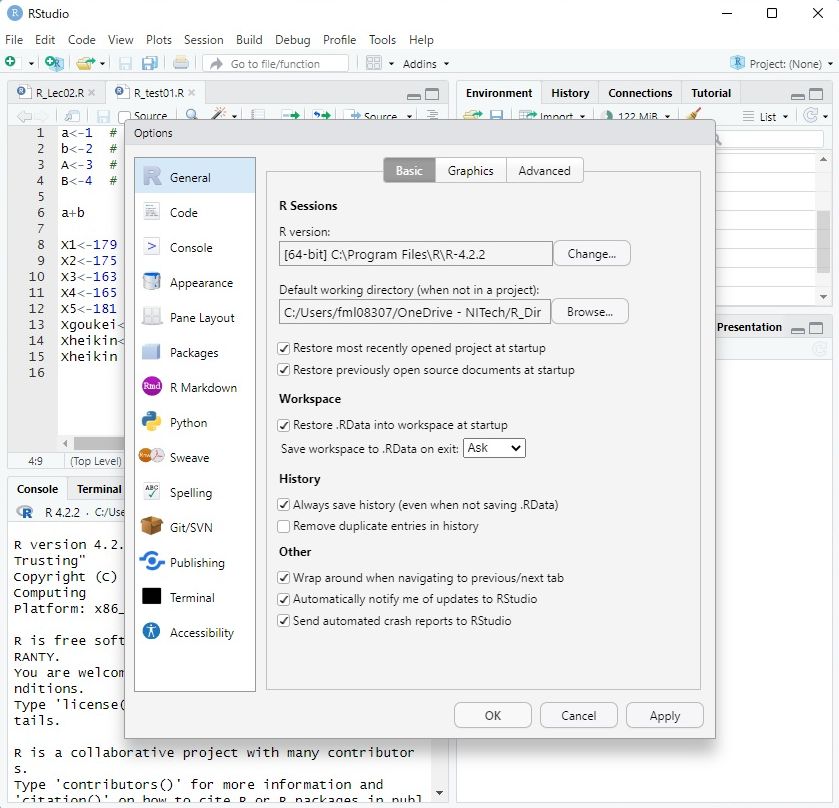
(画面1) (画面2)
6. Default working directoryの確認
現時点の「Default working directory」がどこに位置付けられているかも 確認しておこう。 RStudioを起動直後のSource ペインで「getwd()」を 実行したら、どのように表示されるであろうか? RStudioは前回の利用終了時点の環境を保存してくれるので、 もし前回のRのコマンドが表示されているSourceペインが表示されている場合は、 [File]-[New File]-[R Script]として新しいSourceペインを開いてから試してみよ。
getwd() # 現在のディレクトリを表示(Get Working Directory)## [1] "D:/home_sub3/R_Dir"ご自身の意図・指定したディレクトリが表示されているであろうか。 また、指定したディレクトリは作成されているであろうか。 作成されていないのであれば、4.1節の説明を参考に今回作成しよう。
7. 前半7回を通しての宿題
今回は、RStudioを通してRを使ってみた。 現時点ではまだ自分でプログラムが組めるようになるとは思えないかもしれないが、順に習得していってくれればと思う。 また、プログラムを組むことも大事だが、 得られた数値(統計量)をどのように解釈するかにも注意を払えるようになってほしいと思っている。
【前半レポートの案】「ご自身が興味を持ったデータ」を分析して報告してもらう。- 前半7回を終えるにあたって、各自で用意したデータを分析しレポートとして提出してもらおうと考えている。そこで「ご自身が興味のあるデータ」を見つけてきてほしい。電子化し、分析・報告してもらおうと考えているが、持参後の手順等は今後順に紹介するので、まずは「興味あるデータ」を各自 自力で見つけてきてほしい。 身の回りのデータに注意を払うことを習慣にすると良いかも。
- 5-6回が終わる頃までには確定すること。そうしないとレポートが書けない=単位を出せない。
8. アンケート(ショート課題)
以下で収集するデータの利用目的について説明するので、それにご理解いただけた方は、納得できる範囲で以下項目について「10月08日(火)昼まで」に Moodleのフォームから回答下さい。本日(第1回)の出欠調査を兼ねますので、 最低でも項目a~cは入力できるであろう。なお、期限を過ぎると回答できなくなります。
- 所属、学年
- 「データサイエンス」に抱くイメージや印象
- 利用パソコンとして、ご自身の所有パソコンを利用するか、教育用端末を利用するかをお聞かせください。
- 講義についての要望、取り上げて欲しい内容
- [データ収集] 性別、身長、体重、胸囲、自宅生/下宿生の別、仕送り月額、スマホの月額通信料
- 質問、その他お気づきの点があれば何なりとお聞かせください。
∞. 【時間に余裕があれば以下に進む。無理な場合は来週に回す。】
9. Rでプログラムが書けるようになろう
データを格納するために、変数やベクトル、行列の取り扱いを理解しよう。
9.1. 変数とベクトルを理解する
値を保持させるものとして、英数字で変数を定義できる。 左矢印(に見えるかな?)で値を代入している(定義している)ことを示している。 その際、英字の大文字と小文字は別のものとして取り扱われることに注意せよ。
[操作] Sourceペイン(左上)に1行入力するごとに、「Ctrl+Enter」で実行する。 計算結果はConsoleペイン(左下)に表示される。以下では、薄い灰色部分が Sourceペインの入力を示している。このテキストからコピーペーストすれば手入力の手間を省くことができる。また、複数行を選択(ハイライト)後、 「Ctrl+Enter」をすると、複数行を一気に実行することができる。
なお、新たに定義された変数は、Environmentペイン(右上)に表示される。 また、シャープ記号(#)の後ろは「コメント」であり、Rの実行には無関係である。読者への説明用に記入してある。
a<-10 # 変数aに10を代入
b<-22 # 変数bに22を代入
A<-35 # 変数Aに35を代入
B<-48 # 変数Bに84を代入
a+b # 変数aと変数bを足して## [1] 32A*b # 変数Aと変数bをかけて## [1] 770A/B # 変数Aを変数Bで割って## [1] 0.7291667sqrt(A) # 変数Aの平方根は## [1] 5.916085人の身長の平均を求めてみよう
身長: 179, 175, 163, 165, 181
皆さんのアンケートの中から、任意の5人を抽出して、 この5人のデータに対する処理方法を紹介する。
X1<-179 # 方法1
X2<-175
X3<-163
X4<-165
X5<-181
Xgoukei<-X1+X2+X3+X4+X5
Xheikin<-Xgoukei/5 # 単純計算で求める
Xheikin## [1] 172.6Xvec<-c(179,175,163,165,181) # 要素数5のベクトルの定義(方法2)
Xvec # 定義したベクトルを表示させてみる## [1] 179 175 163 165 181mean(Xvec) # ベクトルの要素の平均値を求める## [1] 172.6[演習9.1-1] 上記5人のそれぞれの体重は以下であった。平均値を求めよ。
体重: 87, 58, 65, 61, 67
Y1<-87 # 方法1
Y2<-58
Y3<-65
Y4<-61
Y5<-67
Ygoukei<-Y1+Y2+Y3+Y4+Y5
Yheikin<-Ygoukei/5
Yheikin## [1] 67.6Yvec<-c(87,58,65,61,67) # 方法2
Yvec## [1] 87 58 65 61 67mean(Yvec)## [1] 67.6【要点】
- ベクトルの生成方法に慣れよ。c()関数のcはcombinationの頭文字の意味。
- 1行ずつ実行するには式を入力後、「Ctrl+Enter」を押す。
- まとめて実行するには、式を複数行を選択後、「Ctrl+Enter」を押す。
- 「#」以降は注釈(コメント)で実行には影響を与えない。
- 特定の要素の値を見るには角括弧で要素番号を指定する。
Xvec[1] # 1番目の要素の値は 179 =1人目の身長## [1] 179Yvec[4] # 4番目の要素の値は 61 =4人目の体重## [1] 619.2. 行列への拡張
統計では、縦方向にサンプル(1人目、2人目、…)を、 横方向に変量(身長、体重等)を2次元的に配置して分析に供することが一般的である。
ベクトルを横方向に連結して行列を作る。ここでは取り上げないが、 新たなサンプルが採取できたような場合(サンプルの追加)は、縦方向に連結することになる。
- cbind()の名称はcolumn bind (列結合とでも訳すのか)
- rbind()の名称はrow bind (行結合とでも訳すのか)
XYmatrix<-cbind(Xvec,Yvec)
XYmatrix## Xvec Yvec
## [1,] 179 87
## [2,] 175 58
## [3,] 163 65
## [4,] 165 61
## [5,] 181 67特定の要素の値を参照するには角括弧で要素番号を指定する。
XYmatrix[1,1] # (1,1)の要素の値は179 =1人目の身長## Xvec
## 179XYmatrix[4,2] # (4,2)の要素の値は61 =4人目の体重## Yvec
## 61XYmatrix[,1] # 2次元目が1の要素を順に表示(=身長を全部表示)## [1] 179 175 163 165 181XYmatrix[3,] # 1次元目が3の要素を順に表示(3人目の要素を全部(身長と体重)表示)## Xvec Yvec
## 163 65[演習9.2-1] 行列に対してmean()を適用したらどうなるか、各自でやってみよ。得られた値は何を示しているのか?
mean(XYmatrix)## [1] 120.1[演習9.2-2] では、身長や体重のデータが格納されて行列に対して、身長の平均値や体重の平均値を求めるにはどのように指定すれば良いだろうか? 各自考えて試してみよ。
mean(XYmatrix[,1]) # 身長の平均値を求める
## [1] 172.6
mean(XYmatrix[,2]) # 体重の平均値を求める
## [1] 67.6[演習9.2-3: 発展] 身長の平均の求め方は判った。では、身長の分散を計算するにはどのように式を書けば良いであろうか。
# 方法1
sum((XYmatrix[,1]-mean(XYmatrix[,1]))^2)/(length(XYmatrix[,1])-1) # 一発で書くと
# 方法2: 方法1の各項を変数に代入して逐次的に値を確認してみる
XHensa<-XYmatrix[,1]-mean(XYmatrix[,1]) # 平均との偏差
XHensaSq<-XHensa^2 # 偏差の2乗
XHensaSqSum<-sum(XHensaSq) # 偏差の2乗和
Xlen<-length(XYmatrix[,1]) # データの個数
XVar<-XHensaSqSum/(Xlen-1) # 分散
XHensa # 平均との偏差
XHensaSq # 偏差の2乗
XHensaSqSum # 偏差の2乗和
Xlen # データの個数
XVar # 分散
# 方法3
var(XYmatrix[,1]) # 身長の分散を求める
# 方法1
## [1] 66.8# 方法2
## [1] 6.4 2.4 -9.6 -7.6 8.4## [1] 40.96 5.76 92.16 57.76 70.56## [1] 267.2## [1] 5## [1] 66.8# 方法3
## [1] 66.89.3. 便利な関数: seq(), rep()
今後(次回でも)利用する関数を紹介しておく。 単体では「ありがたみ」が判らないかもしれないが。
- seq()の名称はsequential (一連のとでも訳すのか)
- rep()の名称はrepetition (繰り返しとでも訳すのか)
seq(1:10) # 1から10まで10個の要素のベクトルを生成(1つずつ順に))## [1] 1 2 3 4 5 6 7 8 9 10seq(10,100,10) # 10から100まで10飛ばしで10個の要素のベクトルを生成## [1] 10 20 30 40 50 60 70 80 90 100rep(3,8) # 3を8回繰り返す## [1] 3 3 3 3 3 3 3 33:7 # 3から7までを順に表示## [1] 3 4 5 6 7rep(3:7,3) # {3,4,5,6,7}のベクトルを3回繰り返す## [1] 3 4 5 6 7 3 4 5 6 7 3 4 5 6 710. ここまでのまとめ
【思い】Rにおけるベクトルと行列の取り扱いや概念を習得してほしい。
【参考】各ペインに何が表示されているかを見てみよう。
- Sourceペイン(左上): 命令、プログラム
- Consoleペイン(左下): 計算結果
- Environemntペイン(右上): 各変数の値
- Historyペイン(右上): これまで入力してきた命令一覧
88. 参考
このページで取り扱ったプログラムだけを抜き出して以下に列挙しておく。
## 5. インストールできたかの確認
3+5 # 加算
5^3 # べき乗
sqrt(5) # 平方根
## 6. Default working directoryの確認
getwd() # 現在のディレクトリを表示(Get Working Directory)
## 9.1. 変数とベクトルを理解する
a<-10 # 変数aに10を代入
b<-22 # 変数bに22を代入
A<-35 # 変数Aに35を代入
B<-48 # 変数Bに84を代入
a+b # 変数aと変数bを足して
A*b # 変数Aと変数bをかけて
A/B # 変数Aを変数Bで割って
sqrt(A) # 変数Aの平方根は
X1<-179 # 方法1
X2<-175
X3<-163
X4<-165
X5<-181
Xgoukei<-X1+X2+X3+X4+X5
Xheikin<-Xgoukei/5 # 単純計算で求める
Xheikin
Xvec<-c(179,175,163,165,181) # 要素数5のベクトルの定義(方法2)
Xvec # 定義したベクトルを表示させてみる
mean(Xvec) # ベクトルの要素の平均値を求める
# [演習2]
Y1<-87 # 方法1
Y2<-58
Y3<-65
Y4<-61
Y5<-67
Ygoukei<-Y1+Y2+Y3+Y4+Y5
Yheikin<-Ygoukei/5
Yheikin
Yvec<-c(87,58,65,61,67) # 方法2
Yvec
mean(Yvec)
Xvec[1] # 1番目の要素の値は 179 =1人目の身長
Yvec[4] # 4番目の要素の値は 61 =4人目の体重
## 9.2. 行列への拡張
XYmatrix<-cbind(Xvec,Yvec)
XYmatrix
XYmatrix[1,1] # (1,1)の要素の値は179 =1人目の身長
XYmatrix[4,2] # (4,2)の要素の値は61 =4人目の体重
XYmatrix[,1] # 2次元目が1の要素を順に表示(=身長を全部表示)
XYmatrix[3,] # 1次元目が3の要素を順に表示(3人目の要素を全部(身長と体重)表示)
# [演習3]
mean(XYmatrix)
# [演習4]
mean(XYmatrix[,1]) # 身長の平均値を求める
mean(XYmatrix[,2]) # 体重の平均値を求める
# [演習5]
# 方法1
sum((XYmatrix[,1]-mean(XYmatrix[,1]))^2)/(length(XYmatrix[,1])-1) # 一発で書くと
# 方法2: 方法1の各項を変数に代入して逐次的に値を確認してみる
XHensa<-XYmatrix[,1]-mean(XYmatrix[,1]) # 平均との偏差
XHensaSq<-XHensa^2 # 偏差の2乗
XHensaSqSum<-sum(XHensaSq) # 偏差の2乗和
Xlen<-length(XYmatrix[,1]) # データの個数
XVar<-XHensaSqSum/(Xlen-1) # 分散
XHensa # 平均との偏差
XHensaSq # 偏差の2乗
XHensaSqSum # 偏差の2乗和
Xlen # データの個数
XVar # 分散
# 方法3
var(XYmatrix[,1]) # 身長の分散を求める
## 9.3. 便利な関数: seq(), rep()
seq(1:10) # 1から10まで10個の要素のベクトルを生成(1つずつ順に))
seq(10,100,10) # 10から100まで10飛ばしで10個の要素のベクトルを生成
rep(3,8) # 3を8回繰り返す
3:7 # 3から7までを順に表示
rep(3:7,3) # {3,4,5,6,7}のベクトルを3回繰り返す